Chapter 3
BUSINESS REVOLUTION, TECHNICAL REVOLUTION -- THE CLIENT/SERVER OFFICE OF THE FUTURE
![]()
While the computer industry faces a crisis, the organizations that use computers are changing both operationally and culturally. At the heart of the changes is a new framework for understanding and using computers. The current changes will result in a resolution of the computer industry crisis first explored in Chapter 1. That resolution will be based on the TQM and BPR principles described in the last chapter. This chapter synthesizes material from the two previous chapters and describes what the computer revolution of the 1990s is really about. Based on the organizational and cultural changes that TQM and BPR have forced, this chapter describes the office of the future, an office based on distributed computer systems specifically designed to meet the needs of self-managed teams.
The computer industry crisis, and the industry leadership vacuum that goes with it, is a sign of revolution. The rapid advances in technology (resulting in children's toys containing microprocessors more powerful than the mainframes of the 1960s) are another clear sign of revolution. Most of all, this revolution has developed as millions of personal computer users, now exposed to graphical interfaces, expect and, in some cases, demand changes. I have described some catalysts of the revolution, but what exactly is this revolution all about?
50
![]()
Are the changes in the computer industry coming from business or technology? The technology has certainly been changing rapidly enough that it is easy to believe that technology itself may be driving the changes all around us. One cannot deny, however, that business has also been changing at least as rapidly as technology. Perhaps the business and technological changes are somehow related? After all, many other technological inventions, including the telephone, the airplane, and the elevator, have fundamentally altered organizations through an intimately linked set of technical and organizational changes. To further explore the relationship between business and technological change, I pose two questions:
| Where is the computer revolution today? In other words,
how are computers being used to run organizations now,
and what changes are coming? | |
| What is the state of business organizations today? Is there a way of understanding the evolving business culture to trace relationships to the technical revolution? |
Although these questions seem rather broad, I feel that they can be adequately answered. As it turns out, there are two revolutions sweeping through the business world that are directly dependent on each other:
- The personal computer client/server revolution is changing
the very definition of computers. Computers are defined by
the ways in which they are used, and client/server is
opening up a world of new uses for computers. In a short
time, users worldwide will view computers in a completely
different light. Effective use of client/server
technology requires a new organizational style -- that is,
a new way of doing business.
- Business Process Reengineering is redefining the way organizations run. More than just replacing laborious and slow processes with smooth and fast ones, it is redefining jobs, responsibilities, missions, and broad corporate cultures. Business Process Reengineering requires vastly different information technology. Without question, BPR isn't possible without new computer systems, and those new systems have to be built in different ways from all past computer systems.
So there you have it: a technical change that requires new ways of doing business and a business change that requires new technology. Which comes first? Which is more fundamental? Is there a way to know where to start? That's what this chapter and the rest of the book are all about.
FREEDOM: THE NEED FOR SELF-CONTROL
In Chapter 1, I used the matrix in Table 3-1 to talk about the problems with downsizing, rightsizing, and focusing on technology alone. For the most part, the focus in that chapter was on the unbearable cost pressures introduced by the need to maintain both mainframe and personal computer infrastructures. With computer
51
![]()
budgets triple those of 20 years ago, these cost pressures have created a legitimate crisis, but there's another, more human dimension to the crisis that I only briefly alluded to in Chapter 1.
Table 3.1 Business/Technology Combinations and Their Results
| Same Business Model | New Business Model | |
| New Technology | Downsizing | Breakthrough |
| Same Technology | Tuning | BPR |
Personal computers are much easier to use than mainframes. Running an order-entry application in a window on a personal computer screen makes this discrepancy painfully clear. An order-entry form doesn't have the mouse-driven interface, pull-down menus, dialog boxes, or any of the other usability features that characterize the modem graphical spreadsheet or word processor. This aspect of the human crisis came up in Chapter 1. But there's more.
In the mid-1980s, several hundred ordinary office workers were surveyed to determine their personal views of computers and technology. When asked about the term personal computers, these office workers without exception instantly thought of two words. The first word, not surprisingly, was friendliness. They did not view personal computers as threatening even though many of the same respondents did admit to concerns about learning to use these friendly machines. The second word explains why friendliness transcended any potential fear. That second word was freedom. In the minds of the surveyed population, personal computers provide users with the freedom to control their lives and the freedom to use that computer power in the way that they feel is best.
PEOPLE (AND DOGS) NEED TO BE IN CONTROL
Martin Seligman is a professor and psychologist who has studied the causes and treatment of depression for several decades. In Learned Optimism (Knopf, 1990), he describes a series of experiments, carried out in the 1960s, that first gave him a clue to the importance of feeling in control. To help you understand the importance of this feeling of being in control, it's worth describing one of those early experiments that lead Seligman to his breakthrough discoveries.
The experiment has two parts: one in which training takes place and the other during which results are measured. During the training phase, dogs are split into three groups. One group is placed into cages where light shocks are administered. The dogs can avoid the shocks by pressing a button with their noses whenever they hear a sound that comes just before the shocks. This group of dogs typically learns very
52
![]()
quickly to avoid being shocked. The second group of dogs receives shocks at the same time as the first group but has no way of avoiding or turning off the shocks. The third group of dogs receives no shocks at all during this first phase of the experiment.
In the second part of the experiment, all three groups of dogs are placed into cages divided into two parts by a low barrier. The experimenters administer shocks preceded by the ringing of a bell. The dogs can avoid the shocks simply by jumping over the barrier. As you'd expect, the first and third groups of dogs learn quickly to jump over the barrier when the bell rings. The second group of dogs, the ones who were unavoidably shocked, lie down in their cage, whimper, and simply accept the shocks they receive without trying any of the behaviors that would prevent the shocks.
Can dogs really get depressed? Who knows? What Seligman does go on to show in his published works is that learned helplessness in people is directly linked to depression. In addition, he shows that optimism, which can be learned, is fundamental to both happiness (or at least lack of depression) and mental health.
Throughout history, revolutions have been fought in the quest for personal freedom. In the workplace, the entire point of the movement toward empowerment and self-management is that individuals who control their own lives feel better and produce better results.
COMPUTERS AND PERSONAL FREEDOM
The personal computer is the first computer that individuals own and control. Once exposed to VisiCalc, many managers knew immediately that they would never do a budget by hand again. Even if it meant sneaking in the acquisition of an Apple II, Osbome, or IBM PC as some form of office appliance or furniture, those managers knew that they would find a way to get that computer into the office. And once in the office, that personal computer was theirs. Nobody told those managers how to use their computers, what software to run on it, or anything else about the use of those personal computers. Those managers, by using their personal computers, were in control of their own lives.
The tripling of computer budgets in companies large and small was not a matter of choice. Certainly every expenditure on the mainframe side of the house was carefully considered and controlled. The acquisition of all those personal computers, the software, and even the networks that eventually grew up around them occurred whether upper management liked it or not. Because computers gave users increased control over their lives, users did whatever they had to do to acquire those machines.
To really understand the power of this phenomenon, consider the success, or lack thereof, of attempts to standardize on software in large organizations. As users acquired spreadsheets, word processors, databases, and project managers, support started becoming a real issue. In addition, the cost of the software itself eventually grew to the point at which central purchasing, control, and vendor negotiation made too much sense to ignore. The natural reaction of most large organizations was to try
53
![]()
standardizing on as small a set of hardware and software products as possible. Given a standard list of products, support could be simplified, better prices could be negotiated, and perhaps the whole messy situation could be brought under control.
In general, most computer purchases are centrally funded. Mainframes are always bought by companies in some central way; few individuals have enough money either personally or in their departmental budgets to buy a mainframe. In the mid-1980s, even though standardization was starting to become popular, most personal computer software was individually funded. Most personal computer software was bought by individuals either personally or out of an individual departmental budget. Even today, thousands of copies of spreadsheets are bought on personal credit cards and then later charged to expense reports. Other copies are bought by mail order and paid for with miscellaneous expense checks. If the process of charging the company gets too complicated, most office workers will buy a $300 ( street price) tool themselves if the gain appears high enough.
The phrase "central purchasing" immediately brings to mind pictures of products being delivered by the truckload to immense central shipping docks. Surprisingly, the dealers who specialize in selling to Fortune 500 companies (dealers such as Corporate Software, 800 Software, and Software Spectrum) report that their average order size is only four units. Big companies may buy millions of dollars of software per year, but even these big companies buy that software three or four units at a time. Those three or four unit orders are all based on personal decisions made by individuals who need particular products at particular times.
As a result, even in big organizations, standardization doesn't work when it comes to software. Some degree of standardization is possible, but only after the fact. Rather than carefully studying the available software products and then analytically picking the best tool or the best vendor, an organization really has to wait until the users vote with their pocketbooks. When the users have picked the products they want to use, the organization can then standardize on those products as the ones that will get the most and best support.
It is because of the very power of the personal computer freedom movement that computers like the Macintosh became successful. When Apple introduced the Macintosh in the early 1980s, the IBM PC had already dominated the corporate computer world so completely that most observers gave Apple no chance of success with the Mac. After all, the IBM PC was a good computer with a wealth of software to go with it, and IBM was the choice everybody felt safe with. Companies large and small were quick to endorse the IBM PC as the safe standard -the one they would support and the only one users should buy.
Nonetheless, because computer purchases are individually directed and in spite of active opposition from most large organizations, the Mac succeeded beyond anybody's expectations on a completely grass-roots basis. As users tested the Mac's features and produced visibly better results, other users exercised their personal freedom to select computer tools, and the Mac took off.
54
![]()
Again and again, this personal freedom has allowed products like WordPerfect, NetWare, and Paradox to appeal to individual tastes, build a following, and take off. On a larger scale, the expression of personal freedom through the choice of personal computer tools has made the growth of the personal computer budget completely inevitable for organizations of all sizes.
IS THE REVOLUTION ABOUT THE CLIENT?
If the spread of personal computers sitting on desktops is such a powerful movement, then perhaps the computer revolution of the 1990s is about those personal computers? In the client/server world, those personal computers are called clients. A client is a kind of customer, a customer who uses services. Stores have customers who buy physical products. Lawyers, architects, designers, and accountants have clients who buy services rather than tangible products. A desktop or notebook personal computer is a client for the services provided by mainframes, servers, minicomputers, and other shared computers. In client/server technospeak, it's obvious that the computer revolution of the 1990s is about the client.
The client is certainly a major driver in today's computer revolution. It is the box that is bringing the revolution in front of the faces of tens of millions of previously uninterested individuals. The client is not only in their faces, it is also showing them a future that is dramatically different than the computer world of the past: an environment that promotes personal choice, personal freedom, and applications that are increasingly easy to understand. Most of all, the future promises a world in which users are in control. That world of clients, however, is not what the computer revolution of the 1990s is about.
Spreadsheets and word processors may make individuals more productive, but they don't pay for themselves. More importantly, personal productivity tools do not, have not, and will not by themselves change the way organizations work. They may enrich Individual jobs and even make life a little more fun, but by themselves, neither personal computers nor their applications truly empower people. If personal computers by themselves were going to significantly accelerate the shift to self-managed teams, surely that shift would already be visible. Read any book about the business revolution, empowered individuals, and self-managed teams, and you'll find that personal computers are not even mentioned.
But what about all the radical changes that the increased use of personal computers introduced? What about all the dissatisfaction people feel when they compare the order-entry application of the past with the personal computer application of today? What about the unbearably high costs of supporting both personal and corporate computers? Don't all of those factors involve personal computers and clients?
55
![]()
YOU CAN'T FOOL ALL THE PEOPLE ALL THE TIME
It is true that most users are dissatisfied with the user interface of mainframe based, terminal-oriented applications. As a result, it is easy to conclude that replacing the user interface will make users happier and more productive. Aside from eliminating complaints, there is a major motivation driving this approach. Most large organizations are run by and around mainframes. Over the past 30 years, billions of dollars have been invested in writing the applications that run on those big computers. The cost of those applications and the cost of potentially converting them dwarfs both the cost of the mainframes themselves and any potential cost savings from simply replacing mainframes with personal computers. If there is a way, though, to move all those mainframe applications into the future by providing them with modem, graphical front ends, then the investment in application code can be preserved, the organization can keep running without disruption, and users will be happy.
Technically, putting a friendly-looking, graphical front end on mainframe applications is both feasible and relatively easy to do. A variety of tools, evocatively named screen scrapers, have been developed to make this job quick, easy, and painless.
A terminal-based application functions by displaying forms, one by one, on the screen of a terminal. The personal computer is capable of fooling the mainframe and acting like a terminal so that the mainframe application can't even tell that it is talking to a personal computer. A screen scraper is a piece of software sitting inside the personal computer that intercepts the forms intended to be shown to the user and makes them available for conversion. Conceptually, the screen scraper scrapes the form off the screen just as a person might scrape wallpaper off a wall.
After the form is scraped, these screen-scraping tools can actually manipulate it in very sophisticated ways with very little work. A field that calls for a product code can be converted into a scrolling list that allows the user to see all the potential product codes, choose the correct one with a mouse, and send the entry back to the mainframe. Features like pull-down menus, mouse support, radio buttons, color, and multiple windows can be added to a 25-year-old application in just a few hours work per form. Best of all, after everything is converted, the mainframe can't tell the difference.
At first glance, an application properly redesigned with a screen scraper looks totally different. The application is often referred to as having a graphical veneer. As a piece of particle board can be made to look like solid oak by gluing a veneer onto it, a programmer can make a mainframe application look like it uses a completely modem graphical interface. There are problems with this approach, though. To really understand them, an example is required.
A large midwestem organization decided to rewrite a 20-year-old application, moving completely to a client/server approach. The application, based around two main-frames with several thousand terminals, processed millions of transactions per day.
56
![]()
Not surprisingly, the job of rewriting the application was projected to take several years. As a first step, the MIS department decided to put a graphical front end on the existing application. With this improvement, the users and customer service representatives around the country could gain some immediate benefits.
After four months of work, the first step in building the graphical veneer was complete. The programmers altered the order-entry application, an application that previously consisted of 93 forms designed to be displayed on the screen one at a time. They converted the 93 forms into 81 graphical displays designed to run in a color, mouse-driven environment based on Microsoft Windows. Management brought in a representative group of users to see and test the new user interface.
At first, the users were very excited. The new interface looked very nice; many functions were simpler to understand; less memorization was required; and the whole thing just plain looked better. After this initial reaction, the group of users went away for two days to really test out the new system. After less than a day, they returned not looking very happy.
The first thing the users discovered was that the new system was not really new, which was true because none of the code on the mainframe had been changed at all. Although a few steps had been streamlined and some functions were more self- explanatory, the fundamental flow and operation of the original was unchanged.
Even though the basic operation of the system wasn't different, the external appearance was totally changed. The application, used by several thousand customer service representatives around the country, depended heavily on an extensive training program, carefully developed documentation, and a sophisticated multilevel help center. All of these supports kept thousands of service reps productive all the time, even in the face of employee turnover, policy changes, and unexpected problems. By changing the external appearance of the system so completely, the MIS department made obsolete their documentation, training programs, help protocols, and problem determination procedures so painfully built up over the years. The cost of rebuilding all that surrounding infrastructure made the cost of building the graphical veneer appear insignificant in comparison.
Even worse, all the really big problems in the system -- missing functionality and built-in inflexibility -- were still present. "Make it better" is what the users said. "We did" was the response of the team that built the veneer. "Did not." "Did too." You get the picture.
Graphical veneers are designed to fool users. They make old applications appear new. In the process, they do bring some benefits in terms of simplification and ease of use. But as Abraham Lincoln said, "You may fool all the people some of the time; you can even fool some of the people all the time; but you can't fool all of the people all the time." Screen scrapers are a fine first step, but that's all they are. Really significant change requires more. The reason is simple: the client is a major catalyst for change, but the real revolution is not about the client.
57
![]()
INFORMATION AT YOUR FINGERTIPS
Bill Gates, the founder of Microsoft and one of the true visionaries of the computer industry, is blessed with an ability to predict future technological trends. For most of the 1980s, he believed that the quest for graphical applications with increased power and ease of use was the chief challenge confronting the industry .In the early 1990s, he forecast that the new challenge will be putting information at people's fingertips. Today, the phrase information at your fingertips (/AYF for short) has become Microsoft's slogan of the decade, but what does it entail?
In the early days of computers, users were excited to be able to build small spread sheets and write better memos with their word processors. If developing a budget or forecast meant reentering information generated by another, often bigger computer, users didn't care. The net result was still far faster than doing the same work by hand. As time passed, spreadsheets got bigger as people packed more and more informa tion into them, and consequently, user requirements began to change.
Today, users still want to use spreadsheets, project managers, and desktop databases to analyze information, but they no longer want to enter all that information by hand. Why can't that information be sucked directly out of the mainframe, resulting in analy sis based on up-to-date data? Once generated, why can't a forecast be immediately shared with other organization-wide users so that they can refine and build on the data without having to reenter any information? People want the computers on their desks to be gateways to information located all over the world; they want to combine data from many sources quickly and easily. That's what I mean by information at your fingertips. Getting it is a problem.
WHY ACCESS (AND PARADOX AND DBASE) HAS NO ACCESS
Since about 1987, marketing surveys of users have revealed that access to corporate data is at the top of everybody's list of desired features. Sure, spreadsheets and graph- ics packages should continue to get better, but for most users, they're already good enough. Most users have no problem manipulating or presenting information effectively. They simply want better access to information.
I've illustrated the problem in Figure 3-1. In most organizations, all the data sits in either the center ring or the outer ring. The center represents all the painstakingly collected and carefully guarded data sitting in corporate databases. Ordinary users are allowed to access that data through specially written query programs -- programs that allow for no flexibility at all. The outer ring consists of all the data sitting on users' desktops. In many companies, there is now as much data sitting here as in the central databases. The data on the desktop is generally entered by hand, completely unshared, and usually out-of-date as soon as it's entered. What's missing is any data in the middle ring. That middle ring consists of data that is the property of the workgroup, team, or department. Many users can share and update such data, but in most companies, that middle ring just doesn't exist.
58
![]()
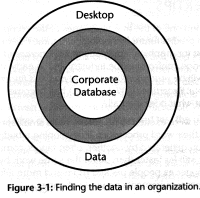
In fact, there is no easy way to create workgroup-level data, so the middle ring actually represents a kind of barrier, an impermeable wall separating the users and their desktop computers from the consistent, up-to-date data sitting in the corporate mainframe. Why does this barrier exist?
The computer industry is certainly aware that users have a need to access data in corporate databases. A variety of desktop databases such as Access, Paradox, dBASE IV, and Approach have been built specifically to facilitate such access. These desktop products in turn connect to a variety of gateway products that typically run on servers to provide the connectivity required to talk to the mainframes and their database software. Paradox, Access, and the other products speak SQL (structured query language) for their users. They pipe this language through to the mainframe and then accept the returned result, hiding the entire complex process from the individuals who initiated the original information request. The software now available allows users to access information, but this very access leads to another completely different problem.
Historically, when talking to audiences that include the operational staff responsible for mainframe databases, I've frequently asked them how they feel about users generating ad hoc queries that run against the databases in their care. The usual response is either an uncomfortable silence or sometimes a strained giggle. Why? Because these audiences find the very idea beyond belief that users might be allowed, let alone encouraged, to run queries generated on the fly against production databases.
Most queries of any interest contain aggregates of one form or another. An aggregate is a sum, an average, a count, or any function that requires the application of an arithmetic operation against every record in the database. Who's the biggest customer? How many red widgets did the company sell last year? What are the average sales by salesperson by territory? All of these questions and more require the computation of
59
![]()
aggregates against either entire databases or major portions of those databases. The problem is that production databases are shared by hundreds or thousands of users all working on the same mainframe. Ad hoc queries bring mainframes to their knees because they often require access to large parts of the database. When the mainframe comes to its knees, the business literally stops running. Worst of all, if users are creating their own queries, then nobody can predict the load on the computer. As a result, not only will the mainframe grind to a halt, but it won't even be possible to predict or schedule that halt. That's obviously not an acceptable situation in a production environment. So in practice, dBASE, Access, and Paradox users are just not allowed to access the real data.
YOU'RE RESPONSIBLE -- JUST DON'T ASK ANY QUESTIONS
Picture this conversation: you're encouraging a group of customer service representatives to become empowered. These people are the same ones who were so unhappy with the graphical veneer. "You are responsible for customer satisfaction," you tell them. "Make decisions, make exceptions, do what it takes, and don't depend on anybody else to solve the customer's problems." A hand goes up. "Can we have access to customer histories? Can we access the information required to understand why a customer order has been refused by the credit department? Can we tell customers why their shipment is late or why they're on shipment hold?" You uncomfortably acknowledge the problem and promise to check with MIS. The MIS department starts talking about application backlogs, overloaded mainframes, and the complexity of handling changes to applications written 20 years ago. So you're in a bind. You want to empower the service reps, but it seems impossible to provide them with the information required to solve customer problems. You can offer only responsibility without the ability to get needed information -- responsibility without authority. That's hardly empowering.
Even unlimited ad hoc access to data is not enough for true empowerment. A large oil company sells approximately a billion dollars of product annually through a group of independent sales agents who represent separate companies with no direct connection to the oil company. Each time an agent makes a sale to one of his or her customers, the price for the sale is set by the company so that the hourly fluctuations in spot oil prices can be adequately accommodated. This form of pricing requires that the sales agents send all orders to the oil company for processing. Customers receive their invoices from the oil company, not from the sales agents. Over time, the process of entering and reentering the orders led to an increasingly high error rate. Customers who received bills with serious mistakes sent them back, and they became annoyed at the perceived poor service. Every year, the agents asked the company for two changes in their overall operation. First, they asked for the ability to generate bills themselves. And second, they asked for the ability to customize the billing program to meet the unique needs of their particular marketplaces. After all, each agent represented a different class of customer, and that was the reason for selling through independent agents in the first place. But the agents were all being forced to carry out
60
![]()
business in a uniform fashion. Each year, right after the agents asked for custom billing and more control, the oil company carefully explained to them why no central system could accommodate the huge number of variations required to meet the needs of the wide variety of market segments the agents covered. Stalemate. And certainly not empowerment. The catch here is that the agents were asking not just for ad hoc access to data, but also for customized programs for changing the data. If MIS staffs have trouble believing in the possibility of ad hoc access to data, they can't even begin to comprehend the concept of customized changes. The programs that change the information in mainframe databases are the most carefully tested, most jealously guarded, innermost of inner circles in the MIS temple.
INTO THE MIDDLE RING
What is the solution to the challenge of filling that middle ring? How can desktop users be provided with ad hoc data access without killing the mainframe? And unimaginable as it may be, isn't there some way that agents, workgroups, and self-managed teams can customize the programs that update the data without breaking the entire database infrastructure built up by MIS? The answer to both questions depends on a new element: the server.
Why can't users run ad hoc queries and ask any question of the database they want? Because it will kill the mainframe. How about if there were more mainframes? Obviously, if there were enough mainframes, users could ask any questions they want. Of course, mainframes are expensive, so this might all be easier said than done. Just adding one or two mainframes still isn't enough. For example, it's easy to imagine having a mainframe for production use and another mainframe just to handle ad hoc queries. Easy to imagine but still far from adequate. Any single user running complex queries could steal the new mainframe away from all the other users. So adding two or three or four new mainframes may not be enough.
Personal computers really have become almost as powerful as mainframes. A shared personal computer with a copy of the mainframe database can answer complex ad hoc queries as easily as a mainframe. Because that personal computer is shared by only a small number of users, it may well answer those questions faster than a mainframe. Also, a personal computer may cost only $5,000, $10,000, or $20,000. Clearly, inexpensive computers can be purchased by the dozens or even the hundreds. Every workgroup can have its own server; large teams can even have several servers. Servers provide access to shared data to several desktop computers, all connected together over a network.
A server can solve the first part of the problem -providing ad hoc access. Remember the case of the customer service representatives with the 20-year-old mainframe application and the new graphical veneer? After careful self-examination, the MIS department decided to rewrite part of the order-entry system even before the larger rewrite of the entire mainframe application was close to complete. For the second rewrite of the user interface to the order-entry application, MIS made some effective changes. Even though the core order-entry software on the mainframe was to remain
61
![]()
unchanged, a great deal of the data about customers, products, and orders was down-loaded to regional servers located in the field. The servers contained copies of the data; all the master updates were still centralized on the mainframe. The use of servers provided a way of making the system better.
The application interface, originally consisting of 93 forms and then converted to 81 window displays, underwent another rewrite. This time, instead of a forms-oriented approach, MlS split the application into two parts. The actual order-entry forms, consisting of only six screens, were left unchanged. The other 75 screens -- designed to allow service reps to answer questions about products and orders -- were completely redesigned. Instead of providing specific screens to answer particular preselected questions, the designers provided the service reps with a series of general purpose query tools for poking around through the entire database of customers, products, and orders. The more general query tool was more powerful, and it involved far fewer screens. In fact, this third version of the application consisted of only 27 screens. Of course, these screens were far more interactive than were the previous 81 or 93 forms. They made extensive use of pop-up windows, drop-down lists, and the like.
When first exposed to the again-rewritten system, the service reps were shocked and discouraged. The new screens, with their dynamic interaction and fluid screen layouts, looked complex and forbidding. Still, they agreed to go away and give the new software a real trial. This time, after two days, the users came back grinning from ear to ear.
The representatives reported that the new screens were not nearly as complex as they first appeared. Each screen packed in a great deal of information and represented an entire world of query-based exploration, but the options available at any given point in time were relatively self-explanatory. In addition, the reps had discovered a new idea. The query tools lent themselves to experimentation. In the old system of fixed forms, experimentation was an alien concept. Either a specific form existed to answer a particular question or the question could not be handled. The new system actually encouraged experimentation. The users felt that the new system might even be fun! After several hours, they concluded that the new system was at least as easy to use as the old one.
Then something really interesting happened. The service reps had elected to try their new system in parallel to the old one. Sitting next to service reps entering orders with the old system at terminals, other reps entered the same orders into the new system at personal computers. At first, the new system was painful to use. It wasn't even possible to keep up with the old system as the reps learned the new software. After a while, the two systems seemed comparable. Then the breakthrough occurred. A customer's order was rejected by the old system. The customer insisted that someone had made a mistake, but the old system provided no way of finding out the reason for the refusal. As the rep handling this customer was about to hang up, his parallel buddy signaled him to hold on. Using the new system and its general query tools, the two reps quickly determined that the customer was on hold because of a late payment. The customer, who had systematically paid all bills on time for over 20 years, was over his credit limit by only $42. The reps made an on-the-spot exception, the
62
![]()
order was processed, and the customer was thrilled. Guess what these prospective users spent the next two days doing? They looked for problems and solved them with their new-found access to data. Even without a direct connection to the real system, the new system of servers, by allowing its users to ask questions, empowered them to solve customer problems.
Obviously, the new system depends totally on having plenty of cheap servers. The alternative, dozens of mainframes, would never have been cost effective. But that's the point. On a small scale, by redesigning the business process to allow service reps unlimited access to data along with the authority to make exceptions to company rules, a self-regulating process is created. That process could not exist without PC-based server technology. The new process coupled with the new technology creates a breakthrough in customer satisfaction (see Table 3-2).
Table 3.2 Business/Technology Combinations and Their Results
| Same Business Model | New Business Model | |
| New Technology | Downsizing | Breakthrough |
| Same Technology | Tuning | BPR |
CLIENT/SERVER: IT'S ABOUT THE SERVER
What about the case in which the users need to not only access the data in unique ways, but also change it on a custom basis? Why can't users and teams be allowed to customize applications that change the data? Programming is hard, so most users might never be able to build the programs that make such customization possible. But that's not the reason. In fact, desktop databases that make accessing data easy -- for example, Approach, Paradox, and Access -- also make it easy to write programs to change that data. Writing those kinds of programs may still require some technical talent, but the task is now simple enough that thousands of consultants and departmental power users are more than up to the task. So the issue is neither complexity nor lack of tools.
In Chapter 2, I associated bureaucracy with three fundamental organizational needs: planning, coordination, and policy enforcement. Two of those, coordination of scarce resources and consistent policy enforcement, essentially amounted to the implementation of business rules. A large part of the mainframe's job is enforcing those rules. In fact, why don't users get to write programs that change data in the corporate data- base? Because the programs they write can't be guaranteed to obey the company's business rules. Because users don't have the detailed training to know what all those business rules are, their programs that change data are guaranteed to break company
63
![]()
rules. The corporate database represents information that has been carefully collected in a way that ensures that no rules have been broken and all data is consistent. So allowing users to change data on their own may render the entire database useless. Pretty horrifying.
The server changes that entire picture. Servers don't sit on desktops. They don't belong to any particular user. In fact, servers can be locked up in a computer room, secured in a wiring closet, or even if they're in the office, protected from users by lock and key. The server is the first computer that can be the property of both the workgroup and the corporation as a whole. MIS can program the server to enforce business rules. That enforcement can be built in so that when teams write their own applications, any database changes that break the rules are rejected. Teams can write their own applications by studying the elaborate documentation describing all the company's rules; or they can, like most users, write their applications pretending that no rules exist. Either way, if their application breaks rules, the application won't run. When the application is fixed so that it doesn't break any rules, then it will run.
Taking advantage of this approach, the oil company in the earlier example wrote a server-based application that allowed agents to enter orders directly. Pricing was still done centrally through a communication link with the central mainframe. The servers, however, produced the actual invoices. Because the servers eliminated the need for the manual reentry of orders, errors virtually disappeared, a fact that both the customers and the agents immediately appreciated. The savings associated with the elimination of the reentry paid for most of the system in less than a year. Best of all, within six months of the installation of the system, over half of the agents developed both customized billing programs and customized data-driven marketing programs. Costs went down, market share went up, and everybody was happy. The server allowed the oil company to retain centralized control over pricing and some other aspects of billing while still allowing the individual sales agents to access data and even modify that data in a customized fashion.
What is client/server about? Client/server is primarily about the server:
- Distribution of processing
- Distribution of data
- Graphical user interface
The server allows data to be distributed across many computers and other servers so that self-managed teams and empowered employees can ask questions often and in complex ways. The server also allows processing to be distributed out to the teams so that they can customize applications to meet their particular needs while still safeguarding company business rules. Without the server, both those forms of distribution are impossible.
64
![]()
Of course, client/server is about the client, too. It's third on the list. Having a graphical user interface is important. Without it, applications are too hard to learn and use. If, however, one element had to be dropped off the list, graphical clients, for all their visible appeal, would disappear before distribution of data or distribution of processing. Mainframes with graphical veneers fool people for a short period of time, but in the long term, they don't lead to any business or organizational revolutions. Providing teams and individuals with unlimited access to data and the ability to customize business procedures to meet their local needs does lead to revolution. BPR and TQM call for these changes. For the best possible revolution, though, try to meet the needs of both the client and the server.
BUSINESS REVOLUTION, TECHNICAL REVOLUTION
In the book Reengineering the Corporation, Michael Hammer and James Champy devote a single chapter to the role of information technology. Every example of reengineering in the book revolves around some critical change in the use of that technology. Ford redesigned its accounts payable department, eliminating the need for vendors to invoice the company for products it purchases. After a product is ordered, a computer database keeps track of the orders so that incoming shipments can be inspected and accepted at the time of arrival. When they're accepted, payment is initiated automatically. Now 125 people do the work that previously required 500. In another example, at IBM credit, a computer system collects the information and business rules required to process a loan application so that a single individual could process the entire application with no outside assistance. In the Ford system, the computer helps manage data. In the IBM system, the computer helps to manage all the rules applying to each loan situation. The results are equally dramatic: loan processing time was slashed from seven days to four hours. These examples illustrate the role of computer technology in making BPR possible. What is not so obvious is that in order to really succeed, BPR requires a change in technology.
The change is a direct consequence of the shift to self-regulating processes and self- managed teams. Self-managed teams are generally not very large -- typically 5 to 12 people in size. The point is to replace task-oriented jobs with slightly larger, self- regulating processes. If the processes and their teams get too big, then they either can't be truly self-regulating or they just have to be divided up again. Self-managed teams, in tum, need access to data and the ability to customize business procedures. Both require access to more flexible computer resources than are possible in a centralized environment.
An insurance company faced with escalating costs in its health care program decided to focus on converting its physicians into self-managed teams. As part of his or her practice, each physician was given more control over the treatments prescribed to patients. No longer would anyone force these practitioners to ask for permission each time a procedure or treatment seemed advisable. At the same time, the company provided the doctors with profitability targets along with incentives to make those
65
![]()
targets happen. The problem was that the doctors needed the ability to access historical data on the fly as they made treatment decisions. They also wanted the ability to customize their office procedures to streamline common operations. Although the doctors' requirements could have been accommodated on the existing mainframe-based systems, the result would have been a need for one mainframe per 20 doctors. The insurance company decided to go with easily affordable, distributed servers that provide the same service. The results included lower costs, better health care, more productive doctors, and a more profitable insurance company.
This example is very similar to the others 1 discuss in this chapter. Companies need to provide individual teams and departments with the ability to access corporate data while allowing them to change some of that data to meet their local needs. Banks, insurance companies, retail chains, distributors, travel agencies, hotels, and many other businesses all face the same problems. Self-managed teams need self-managed databases and applications. Servers with distributed databases are the key to making this happen.
The new organization calls for new technology; the new technology requires new organizational structures to pay for the change. Put the two together, and a break- through will happen.
A DIFFERENT WORLD
Today, there are about 30,000 mainframes spread around the world -probably as many mainframes as there will ever be. In addition, there are approximately 300,000 super mini-computers, such as the AS 400 and the larger VAXes, that run smaller companies and departments of larger companies. Altogether, the larger companies of the world are run by about 350,000 large computers of various kinds. In thinking about the computer revolution of the 1990s, most prognosticators assume that clients and servers will replace those big computers. Being generous, that assumption would imply replacing or augmenting 350,000 big computers with perhaps one or two million servers.
Each of the big computers is sold through a direct sales force. Because each big computer represents a highly specialized technology, each requires extensive installation and support. For example, CICS, one of the major components of the IBM operating system, can be installed only by either IBM personnel or highly trained customer-employed gurus whose only job is to keep it running. Changes to big systems won't be simple.
The United States Congress recently passed a law providing family leave under special circumstances to all employees working for companies with more than 50 workers. In reporting on this statute, the August 15, 1993, issue of the New York Times drew on census and Bureau of Labor data and found that only 4 percent of American companies had over 50 employees. Of course, this 4 percent of the corporate sector represents 34 percent of the workers in the United States. Putting this another way, 66 percent of working Americans work for companies with fewer than 50 employees.
66
![]()
These companies obviously don't have mainframes or super minicomputers, but many have computer systems or will have them by the end of the decade. So how many servers will there be in the near future?
In the United States alone, there are over 11 million business establishments. A business establishment is a location that at least one worker reports to on a full-time basis. By the turn of the century or shortly thereafter, every business establishment in the country and most of the business establishments in the rest of the world will have at least one computer. Each establishment is likely to have a server, too. In small locations, the server and the desktop computer may be the same. In larger establishments, the server will be separate and dedicated, and in the largest establishments, there may be many servers.
These servers will process orders, manage inventory, schedule shipments, balance accounts, reserve seats, issue paychecks, and carry out all of the hundreds of other tasks required to keep an organization running. Servers will run around the clock at most establishments, doing work even when no employee is present to initiate new requests. The servers of the world will be the brains and nervous systems of the organizations around them. Servants of their local self-managed teams, these servers will help create a world of self-regulating processes and empowered employees.
In such a world, information at your fingertips will be reality, but the computer industry that helped make it real will be quite different from what it is today. If there are currently 11 million business establishments in the United States and probably 30 million worldwide, then the world of the future is likely to have from 50 million to 100 million servers.
A direct sales force cannot sell 50 million servers, and all of them can't be installed and maintained by a few carefully trained gurus. Servers and the software that makes them run will become the next major packaged-product boom driving change and growth in the computer industry. To get there, though, servers have to become more like everyday appliances.
The business process revolution combined with the client/server revolution will cause major changes. The road to change is a little hard to predict, but the final result, at least today, seems relatively clear.
The rest of this book describes the underlying technology that will make all the changes possible. First, I will describe and explain the technical elements of the client/ server world. After presenting that information, I describe the ways in which the client/ server applications of the future will be designed.