PART III
DESIGNING AND BUILDING CLIENT/SERVER SYSTEMS
| Chapter 11: A Conceptual Framework for the Future
Chapter 12: Application Architecture: A Better Way of Designing Applications Chapter 13: Designing Distributed Systems: Processes versus Databases Chapter 14: A Client/Server Methodology Chapter 15: Tools: Implements for Building Systems Chapter 16: What Distributed Systems Are Made Of |
311 331 357 379 413 416 |
The goal of Part II was to provide a clear and perhaps even exciting picture of the client/server systems of the future. That part did not, however, provide a clear picture of how to design such systems.
Today programmers design and build large business-oriented applications using tools and methodologies developed over the last 30 years. Although many of those tools and approaches are still appropriate, clearly some new elements are required. That's what Part III is about.
When writing a section such as this one, it is tempting to immediately treat the material as a cookbook. After all, previous chapters provided lots of philosophical foundation; why not start dictating specific recipes right away? Because even with some new building blocks in place, technologists must base tomorrow's systems on a conceptual framework different from those in systems of the past. The first two chapters in this part develop a new application architecture to guide the design of a new generation of systems.
The very concept of an application architecture turns out to be both important and powerful. Even if you never build a distributed system, even if you continue to build only mainframe-based systems for the next 1,000 years, the application architecture developed here will still help you design better systems for that mainframe. Better means more quickly developed, easier to change, friendlier to use, and more able to work flexibly with many other systems. That's a tall order, but that's what application architecture is about.
After Chapters 11 and 12 develop the application architecture, Chapters 13-16 describe the specific methodologies, tools, and infrastructures required to build client/server systems. Like Part II, Part III is written specifically to be useful and readable to technical and nontechnical readers alike. Rather than repeat the rationale for both types of readers, I'd rather say this: if you haven't read the introduction to Part II and are looking for motivation to read the next six chapters, go back and read that introduction now. Otherwise, welcome to this section, and as the book's introduction said, have fun.
311
![]()
Chapter 11
A CONCEPTUAL FRAMEWORK FOR THE FUTURE
How will the distributed, client/server business applications of the future get built? How does the process thinking so central to reengineering find its way into the database thinking that drives most application design? At a more mechanical level, if self-managed teams call for intrinsically distributed systems, how do you design and build those systems? This chapter sets out a broad conceptual framework for designing client/server applications. By itself, the framework does not answer all relevant questions. Instead, the framework lays the foundation for answering the questions in the following chapters.
In laying out this framework, I deal with both the present and the future. First, I look at the framework that has evolved for building the applications commonly running today. This framework is fundamentally inadequate; in particular it makes it hard or even impossible to build distributed, client/server applications that meet the needs of self-managed teams. Nonetheless, it is important to understand that framework to see why and how it falls short. For this reason, I spend several pages exploring the foundations underlying today's mainframe-oriented applications. Only when the existing framework is clear can you see how it can be augmented and changed to deal with the future. Perhaps it is tempting to skip to the end of the chapter and see the final answer. And perhaps it is a little frustrating to have to spend time and energy understanding what is just to get to what will be. In the end, however, the effort is worthwhile.
312
![]()
First, approaching tomorrow's conceptual framework in this way ensures that the mistakes of the past are not repeated. Second, it lays the groundwork for understanding not only how to build the systems of the future, but also how to make them blend smoothly with the systems of the present and past.
PHYSICAL DESIGN VERSUS LOGICAL DESIGN
Can distributed systems really be built, and how? Computer professionals have been struggling with this question for 20 years. To resolve this question, you must understand the distinction between physical design and logical design. Physical design talks about computers, disks, databases, communications lines, and other concrete elements of the real world. A great deal of the discussion about client/server systems deals with mechanisms for building distributed systems by jumping immediately to a discussion of what hardware should go where. Should customer data be centralized or be kept in local offices? Is it better to have a small number of big servers or a large number of small servers? Logical design, on the other hand, talks about the structure of the application independent of the type or location of hardware, software, and data. The central point of this chapter is that a good logical design makes client/server possible; without that logical design, distributed systems are almost impossible no matter how the boxes are arranged. So forget about distributed versus centralized for now, and focus on better application structure. After you've built better applications, you can look at how to distribute them -- if it still makes sense to do so.
APPLICATION ARCHITECTURE
How do you go about designing the logical structure of an application? By using an architectural model for talking about applications -- an application architecture. The nontechnical person may think that architectures are abstract, technical, and hard to understand. The analyst, programmer, or development manager may believe that most of the architectures seen recently have no real substance -- that they're really marketectures concocted to make a particular product line appear more advanced than the competition. However, a good application architecture provides a framework for thinking about, designing, building, and deploying applications that fit together and work well.
People have been building computer programs for about 40 years, but they've
been putting up buildings for thousands of years. Drawing from that older
experience of building construction, we can distinguish three distinct phases of
the process of development:
- Architecture. Develop a broad plan for the overall shape of the structure, how it will look on the outside, how the floors and floor plans will be laid out to meet the needs of the inhabitants, giving the building its personality and character.
313
![]()
- Engineering. Design the internal physical structure to support the
shape and goals laid out by the architecture, taking into account strength,
efficiency, and construction costs.
- Construction. Build the structure using construction tools and physical materials.
In designing an application, the first and most important step is to ensure that the application really meets users' needs. Only then do engineering considerations related to strength, cost, and efficiency come in. After the engineering design is done, construction can begin. So the first task is to understand what the application is supposed to do. Based on the application's functions, you can determine which application structure will best meet those needs.
First, I want to look at the architecture of today's applications. Remember that the architecture I'm about to examine is fundamentally inadequate for building the distributed systems of the future. I want to look at that architecture and then discuss where and why it's wrong.
QUESTIONING MAINFRAMES
Because mainframes have been running the business for over 30 years, we must ask the following question: what does a mainframe do for the business? This is the first of four questions that drive the thinking for the next few chapters of this book:
- What does a mainframe do?
- How can servers replace part of a mainframe?
- How are distributed databases designed?
- Are distributed systems technically practical?
WHAT DOES A MAINFRAME DO FOR THE BUSINESS?
Chapter 8 explored why mainframes were more than just big, fast, expensive personal computers. However, what business function does the mainframe play? Why do companies even buy those computer systems to begin with? Superficially, the answer is to run the business. If you probe, you quickly get technical answers such as "It runs MVS, IMS, and VSAM." However, those are facilities on the mainframe that merely support business functions.
To understand what people think mainframes do, look at various proposals to replace mainframes with client/server systems. Seminars, sales presentations, and internal planning sessions yield similar views of a client/server application architecture:
314
![]()
| Front end. All applications have a front end, increasingly based on
a graphical user interface (GUI). Today some front ends may still run on
terminals, but everybody agrees that soon all front ends will run on
personal computers. The role of the client is clear; it runs the front end,
providing the interface to the user . | |
| Back end. The majority of production data resides in non-relational databases. However, there is surprisingly strong agreement that the client/server systems of the future will revolve around structured query language (SQL) and relational databases. |
Table 11-1 illustrates the industry-standard application architecture.
| Layer | Contents |
| Front end | Desktop application, graphical user interface |
| Back end | Database, relational SQL |
| 1970s | Databases, terminals, and networks |
Essentially, here's what the table says:
| Simple applications, those that don't require a large shared database, can
be built on the desktop alone. | |
| More complex applications require two layers: one for the desktop application and one for the database. The database can run either on the same personal computer as the desktop application or on a server. Either way, when the application gets more complex, classifying the database as a separate architectural layer becomes important. |
From this architecture, some people may conclude that the mainframe is a database. At one level, this answer is understandable. However, at another level, this answer is actually wrong. Unfortunately, many people, including most of the computer industry, believe that mainframes are just databases.
Certainly the personal computer industry appears to view mainframes as very
big databases. Listening to people in the industry, the prevailing belief
maintains that "if we could just build big enough (multiprocessor) servers,
robust enough operating systems, and sophisticated enough database software,
those servers would finally replace the mainframe." There are many reasons
to hold this belief:
| Many servers are either file servers or database servers. All the more sophisticated servers are sophisticated exactly because they run databases such as Sybase, Oracle, and DB2/2. |
315
![]()
| The servers connect to mainframes primarily to access databases. | |
| Organizations use servers specifically to replace mainframe databases. | |
| Organizations keep applications on the mainframe usually for better database performance, database integrity, and database functionality. |
It's little wonder that PC hardware and software professionals view the mainframe as merely a big database. What's more surprising is that many mainframe professionals hold this view, too. The primary argument always made by mainframe people is that -- even long-term -- the mainframe is at least as good a server as a PC, and perhaps even better. And because the mainframe is being portrayed as a better server than a PC server, the picture is clear. PC servers and mainframe servers compete in the back end layer; they're both essentially databases. The picture of the mainframe as a database may be clear, but it's also wrong; the mainframe is more than just a database.
What's wrong with this picture? On the front end, is there more than graphical desktop applications on a PC? And on the back end, are there more than databases, which are sometimes on servers and sometimes not? To answer these questions, think about a few more questions:
| Where's COBOL? Worldwide, over 2 million programmers continue to
list COBOL as their primary programming language; it is the most heavily
used language by those who program for a full-time living -- by far. Where
is COBOL in the architectural picture? |
| On the front end, are people using COBOL to develop graphical
applications? Not a chance? For many developers who grew up with personal
computers, BASIC is their language of choice. And certainly Microsoft,
with Visual Basic and Access Basic, has provided powerful tools for
building graphical applications quickly. Other GUI developers swear by
SmallTalk and its relatives, such as Enfin. For highly technical work and
dyed-in-the-wool hacking, there's no substitute for C and C++. And, of
course, tools such as PowerBuilder and Notes either bring along their own
notations or build on one of the languages I've just mentioned. COBOL is
not particularly well suited for highly graphical front ends. It can be
done, but why bother? So no COBOL here. | |
| How about the back end, where you'd expect to find COBOL for sure? Yes, except that now we've defined the back end as the database, and the language we're working with is SQL. Even if you use an object-oriented database (OODB), the language will still not be COBOL; it will be SmallTalk or C++. So there's no COBOL here, either. |
316
![]()
Unfortunately, industry seminars are presented every day with this two-layer architecture either implied or spelled right out but leaving no room for COBOL in the picture. COBOL isn't even acknowledged. It's as though the language died so long ago that everybody's forgotten it ever existed.
| Where do CASE-generated programs reside? Many leading CASE tools
generate code for applications. When the CASE tool generates its COBOL or C
code, where is it used? Not in the front end and not in the back, for
the same reasons I've already discussed, so where does the CASE code go? | |
| Where do the business rules go? This is the core question, the one I'll use to expand the architectural model to include a third layer. Taking a few examples, where does the code go that: |
| Makes credit-authorization decisions involving hundreds of rules and criteria? | |
| Runs a blacked-out warehouse containing millions of dollars worth of inventory, routes robot forklifts, schedules trucks, and tracks every inventory item? | |
| Manages seat assignments and reservations for an airline? |
Each of these examples involves hundreds of thousands of lines of code that is not database code and is not front end code. This code runs business processes consisting of hundreds and thousands of business rules. The code that executes business rules is typically written in COBOL or generated by CASE systems with only one goal: to implement business rules. Where does all this code live?
| Where's batch? Remember all of the big programs 1 talked about in Chapter 8? Those big programs have no user interface components and certainly don't run on a desktop. They use a database heavily, but are not themselves either databases or database code. Rather, these batch processes also revolve around business rules and business processes. |
This discussion enables me to answer that first of four questions, figuring out finally, from a business perspective, what a mainframe does. As I'll soon show, the mainframe runs business rules, providing a home for COBOL and CASE-generated code a place where batch programs can live happily. Understanding the true role of the mainframe answers all these tricky questions behind the bigger question of what the mainframe really does.
MAINFRAMES AND BUSINESS PROCESS AUTOMATION
Historically, the mainframe has been the central engine that runs the business by implementing all the business rules that keep the organization running. Business Process Reengineering makes the mainframe more -- not less -- important as the key engine that makes all the business rule-centered processes even more automatic. If
317
![]()
you want to replace mainframes, it is that central function -- the execution of business rules -- that you better replace in a highly effective fashion. The central role of the client/server systems of the future will be running those business rules.
Suppose that you could keep track of every second of a mainframe's processing; what would you find out? Some of the time would go to the operating system (OS), the computer equivalent of administrative overhead. Ignore that part of the time. On most big mainframes, what's left is split about 50/50. Half goes to the database. Yet organizations don't use relational databases for high-volume applications precisely because they can't afford more than half of non-OS processing for databases. They have to reserve the other half of the computer's time -- half of its cycles, as computer people say -- to the application. Which brings me to the next question: what's an application? Generally, applications are software programs that deal closely with how an organization spends its time. To understand these applications, consider some everyday business processes.
When a customer rents a car, how long does the rental company retain a record of that rental? For the few minutes it takes to process the customer through the checkout stand? No, much longer than that. At a minimum, the car rental company retains a record of the rental until the car is returned a few days later. If the car is returned damaged, the company holds the record until all of the damages are paid. If the damage is particularly bad, the rental agency retains the record so that if this customer frequently damages rental cars, eventually the customer's status can be changed to prohibit further rentals. An apparently simple rental is a much more complex business process, requiring many steps and potentially lasting days, weeks, or even months.
Many business processes easily stretch into months. For example, stores order products, track their popularity, and adjust future orders to match customer demand. That process stretches over months and years.
In large companies, processing single orders can take months or even years. The order may be staged over many shipments -- with products that require special manufacturing runs, complex shipping schedules, and deliveries all over the world. Even after delivery, invoices have to be cut, payments tracked, and commission payments computed. Then various accounting entries have to be made at the right times, and all entries must be reflected in monthly, quarterly, and annual reports. In other words, organizations of all sizes spend their time in complex business processes that consist of many steps over a long time.
Who keeps those processes running? For example, when a customer's bill payment is late, who decides that it's overdue? Who remembers to send out a reminder letter, schedule a phone call, and eventually change the customer's status to refuse additional orders? Who arranges for large orders to be shipped to many countries -- with manuals in the right languages? Who injects parts of the orders into manufacturing runs at just the right time? And who sends out the invoices, ages them (remember the big batch process), tracks payments, calculates commissions, and posts these actions to the accounting system? The mainframe, of course, during the time reserved for running applications.
318
![]()
Taken separately, mainframe applications complete specific tasks. Taken together, the overall set of mainframe applications is the engine that makes business processes work. Therefore, the mainframe's true central role is running business processes. Maintaining the database, making data available company wide, and coordinating access are important -- but distinctly secondary roles. The database, important as it is, really exists first and foremost to support the business processes. That support justifies the mainframe as the invaluable business process engine.
Is the mainframe, or its replacement, becoming more or less important as a business process engine? Think back to one of the primary design principles of Business Process Reengineering: the elimination of queues. To understand the role of the main- frame in making that happen, imagine that the interface to the mainframe is the smooth surface of a lake at dawn. The applications and processes running inside the machine are the fish swimming beneath the surface. Periodically, a fish jumps out of the water, causing ripples to spread over the entire surface of the lake. Those jumps correspond to processes requiring human intervention. Orders need approval; special shipments have to be scheduled manually, and so on. These human interventions disturb the system. Each time an application needs help from a person, a request is put on a queue, delay is automatic, and the process is suspended until a human completes the task. These queues, or delays, cost money and slow the system down.
Business Process Reengineering is about eliminating those queues. In the course of reengineering a process, each step, each intervention, each request for help or a decision is analyzed.
| Can the step be eliminated altogether? Is the analysis, approval, or
decision really necessary? | |
| Can the decision be made when the process is initiated -- by the person?
If the decision is made early on, then the process won't be delayed by the
decision later. | |
| Can the decision, analysis, or approval step be handled automatically? Can the business rules be put into a computer program so that the rules can be applied automatically without human intervention? |
Ideally, then, the business processes would be completely automatic, with no delays and no human intervention. The surface of the water remains almost completely still with fish disturbing the calm only occasionally. Of course, like all ideals, this one will never be achieved. In fact, having organizations run completely automatically, with no human intervention, isn't even desirable. The point is not to achieve total automation, but instead to eliminate unnecessary queues, unnecessary approval, and unnecessary human intervention. The computers do their part, leaving the people with the decisions that really benefit from human input. Although even this ideal may take a long time to realize, it is at least appropriate. Achieving this ideal -- eliminating all unnecessary queues -- makes the role of the computer as business process agent more important than ever.
319
![]()
In this scenario, is the mainframe more or less important? Far more important? The more automatic the processes become, the more critical the need for an engine to coordinate, sequence, and ensure the smooth operation of all those automatic, multistep processes. The mainframe, or its replacement, becomes even more critically important in the reengineered future than it was in the task-focused past. Again, the true point here is not that mainframes should be eliminated per se. The point is that the function the mainframe performs, namely the automation and execution of business rules, becomes more important than ever. As you think about replacing all those mainframes, it is that central function, the automation of business rules, that you really should be thinking about most.
There is now a complete, business-oriented answer to the question, what does a mainframe do? A mainframe is a business process automation engine. It manages the execution of the business processes that keep the organization running. The mainframe is the master of extended time. It runs individual applications that complete particular tasks. Much more importantly, the mainframe runs the processes that extend over time. When a customer rents a car, no employee has to worry about remembering when the car is due back, whether the customer has damaged cars too many times in the past, and whether a specific car is available to rent. The computer handles these responsibilities. When a salesperson finally wins that big order for products to be delivered over three years, he or she doesn't have to sort out how to get products delivered in 17 countries, in six different languages, all staged over a three-year period. The mainframe arranges all shipments, ensuring that all of the right steps happen at just the right time -- a month later and three years later. Commission payments? The computer triggers those at just the right time, too. Because mainframes can manage complex processes over long periods of time, business process automation is possible. By eliminating the individual schedulers, rule interpreters, and other specialists who used to run the processes one task at a time, the computer liberates workers to make those processes simpler, faster, and most automatic. The mainframe is the automatic transmission of business process automation. And when you eventually replace one or more mainframes, it is that automatic transmission, that business process automation function, that you will most need to replace.
BUSINESS RULES, BUSINESS SERVICES, AND BUSINESS AUTOMATION
How does the mainframe manage and implement all these business rules that keep the organization running? The answer is by running applications. The primary role of the applications running in a mainframe is to implement business rules. Business rules are all of the thousands of rules that define how the business runs.
Business processes, the same processes that Business Process Reengineering is all about, are business rules; in the end a process is just a collection of these business rules. Some managers and consultants may object, saying that defining processes in this way sets up a very bureaucratic view of the world. Perhaps, but computers in the end are mechanical devices, and the processes I am focusing on are the ones best
320
![]()
suited to mechanical interpretation. Furthermore, to the extent that reengineering encourages workers to focus on the automation of processes in this way, it too is encouraging workers to focus on the mechanical element in organizational functioning. Most of all, the key to thinking of processes in terms of rules is that it allows the computer to automate the mechanical parts of the business, leaving only the truly empowering and creative part to people.
So if the applications that mainframes run are composed of sets of business rules, what do these business rules look like? How do they relate to the larger processes that reengineering focuses on? The answer is that the applications, built from business rules, implement the individual steps which define the larger business processes that keep the organization running. Here are some examples of the types of business rules I am talking about, as they relate to a company that builds, sells, and ships products. Notice that each of the examples consists of one or two rules that allow some step to happen in the bigger process of building and selling products:
| The minimum order size accepted by the factory is $5,000. Orders that
involve multiple shipments must total over $50,000, and no single shipment
can be less than $2,500. | |
| Commission payments are made after payment is received from the customer.
Commissions are normally paid at the rate of 5 percent of the amount of the
sale. However, when the customer pays his bills late, the commission is
reduced by 10 percent for each 30 days the payment is late. | |
| Normally, orders are filled on a first-come, first-served basis. However, when there is insufficient inventory , the customer classification number is used, with Class A customers served first, then Class B customers, and so on. |
Those are examples of business rules. Superficially, it's not hard to imagine what a rule looks like. Generally, the form is If A then B. Sets of rules define business processes. Rules may be applied all at once or they may be applied in various sequences over long periods of times. In the preceding section, I introduced the concept of extended time; processes that happen over long periods of time are said to occur in extended time. Extended time is introduced by rules based on events that in turn occur at particular times. For example, interest is charged on invoices when they have been outstanding for over 30 days. Phrased as a program statement, the rule states that If invoice outstanding > 30 days then charge interest. The command charge interest, in turn, would trigger a set of business rules that specify the conditions for determining how much interest is due. Historically, most people have thought about computers as dealing with transactions and other events that last a short time. The essence of business process automation, however, is dealing with processes that extend over long periods of time. That's why the idea that applications can deal with business rules in this world of extended time is so important.
321
![]()
At last I can talk about the fundamental problem with the architecture used to build applications today -- the fundamental problem that makes it so hard to even think about, let alone build, distributed applications. Today's application architecture provides no explicit home for business rules.
Where do the business rules fit into the application architecture? Simply
create a layer just for them. As Table 11-2 shows, the new business rules layer
lies between the top and bottom layers. These two layers have been renamed, too,
to provide names that more correctly describe the functions of all of the
layers.
| Layer | Contents |
| Documents | Desktop application, graphical user interface |
| Business rules | Business rules and computation processes |
| Data management | Database (relational and SQL) |
The easiest way to explain the functioning of the new architecture is to illustrate with an example. Suppose that a customer is renting a car:
| The staff member working at the checkout counter is running a desktop
application program in her personal computer. As part of the document
layer, the desktop application presents a series of documents (forms)
on the screen about available cars, customers, outstanding charges, and so
on. When enough information has been entered for a complete business
request, the document layer sends a request to the business rules layer. | |
| The business rules layer contains computational programs that understand
the business rules associated with various task requests. One such program
processes checkout requests: checking whether the customer has a
reservation, whether the type of car requested is available, and determining
the rental rate. | |
| As the business rules layer does its work, it periodically interacts with the database layer. The business rules layer retrieves database records for customers, cars, and rentals. When all of the checking is complete, the business rules enter transactions to record rentals, payment of charges, and vehicle status. |
What is the real difference between these three layers? Particularly how are the business rule and data management layers distinguished? Table 11-3 formalizes the functions of the three layers. The paragraphs after the table describe each layer in detail.
322
![]()
| Layer | Responsibility | Functions | Tools |
| Document | Understandable, efficient interface | Presentation, navigation, manipulation, and analysis |
Graphical tools and languages |
| Business rules | Policy: rules and heuristics | Decision making, policy enforcement, and resource coordination |
C, COBOL, rule processors, BASIC |
| Database | Consistent, secure data | Consistency, security, integrity, and safety | Databases, database languages |
At the top is the document layer often also talked about and thought of as the "desktop application " layer. The responsibility of the document layer is to provide the user interface for the overall system. This layer is the most challenging to find a name for. Users think of the programs running on their desktop as applications or tools. Yet the developer of the overall system thinks of the business rules and database components as part of the application, too. In the final analysis, the basis for naming the layer revolves around what is actually presented to the user on the screen: documents. The document may be a form, a graph, a memo, or a piece of electronic mail; all of these are documents. Hence the name.
The document's responsibility is understandability and efficiency. Understandability is what GUIs are all about: presenting information in a clear format; allowing the user to control the computer without learning complex commands. Applications must also help people get the work done quickly; that's efficiency.
Understandability and efficiency are critical, but what does a document enable people to do? The function of the document layer is to provide the user interface to the overall system. Superficially, user interface refers to application windows, mice, ease of use, and other stylistic considerations. These are important, but the document layer is responsible for a great deal more:
| Navigation: The document provides a menu, form, and command
structure that allow users to find what they need -- whether it's a command
to run or a report to print. | |
| Presentation: Documents displays information in various forms,
including graphs, sounds, words, and numbers. | |
| Manipulation: The document can be used to create and change information to meet the needs of the user. |
323
![]()
| Analysis: By combining presentation and manipulation functions, the document allows the user to perform what if analyses for a decision, answer, or result. |
In the aggregate, the document layer transforms the personal computer into an electronic desk (see Figure 11-1). The other two layers inject information into that desk. When the document layer receives the information, it becomes the user's to work with. What makes the client/server system so empowering for users is that the document layer allows the user to work with and transform data. Unlike a terminal, which just presents data under the control of a distant computer, the document layer creates the possibility that a computer may also be present on the user's desk. That computer not only presents information and enables the user to enter data into forms, but it also enables the user to work with all the information injected into the layer by using personal productivity tools. The idea that spreadsheets, word processors, and other tools can be used to manipulate information after it enters this desktop layer creates a great deal of personal empowerment for users.
Figure 11-1: The electronic desk in the application architecture.
Finally, the software in the document layer is built with graphical tools, languages such as SmallTalk and Visual Basic, and high-level applications like Excel and Paradox.
The business rules layer is responsible for implementing the organization's policies. Policies are more than just rules. A rule is a precise statement, usually in the form of a syllogism (If... Then...). In practice, many of the decisions handled in the business rules layer are less precise than this. Instead, the software in the business rules layer is based on heuristics. A heuristic is a guideline that is often couched in probabilistic terms. For example, If the customer pays most of his bills on time, let him go over his credit limit a little. The terms most and a little prevent this statement from being a
324
![]()
precise rule. Nonetheless, it's easy to imagine a business rule process that implements this policy by using a combination of percentages, trend analysis, and occasional requests for human help. So the business rule layer is responsible for rules and for heuristics.
Furthermore, the business rules layer implements rules and heuristics in the form of decisions. These decisions fall into three broad categories:
| Formal decisions involve explicit requests for authorization. Is
this transaction within the customer's credit limit? Can the order be
shipped by Thursday? Will the company lend $7,500 to finance the purchase of
this particular car? In these cases, a process in the business rules layer
makes an explicit decision or answers a question. | |
| Policy enforcement decisions are implicit. Although a question may not have been asked, the business rules layer also enforces the implicit rules. Here are examples of policy-enforcement decisions: |
| Customers with outstanding orders can't be removed from the database. | |
| Managers can't approve payments that exceed the manager's authorized limit. | |
| No single shipment can tie up more than 10 percent of the available inventory in stock for critical products. |
These policies are enforced continuously -- even though nobody explicitly asks questions that mention the rules by name.
| Resource management decisions are also implicit. Here are some examples of resource management decisions that the business rules layer makes: |
| Accepting orders only when inventory is in stock | |
| Cutting off seminar registration when seats run out | |
| Managing the scheduling of shipments to optimize delivery times |
As with other types of decisions, resource management decisions are if...then decisions. However, resource management decisions affect resource assignments rather than return yes/no answers to questions.
In the business rules layer, COBOL finally has a home! The software components that define policies, business rules, and complex scheduling algorithms are most like the large-scale COBOL applications of the last 30 years. In addition, programmers can generate business rule components with CASE tools in rule-based systems and with even newer classes of tools. Believe it or not, BASIC may have a role in defining many types of business rule processes. Even spreadsheets may be solid foundations for expressing certain formula-based rules and heuristics. Programmers could use these
325
![]()
and other tools to develop computational programs that implement the decisions, policies, and rules for running business processes programs over extended periods of time.
The database management layer is responsible for maintaining consistent and secure information. A well-designed database management layer maintains data security and data consistency while delivering good performance. The following sections provide more information about data security and data consistency.
DATA SECURITY
The main purpose of the database management layer is to ensure data security. A system must never accidentally lose the information it acquires. That's the point of elaborate backup procedures, expensive tape drives, and mass storage systems. Additionally, the database management layer must also make data available only to those who have a right to see it.
DATA CONSISTENCY
Consistency ensures that corporate presidents don't become irate, that corporate vice-presidents will get the same answers when attacking a problem, and that many files and tables can be linked together in meaningful ways. Therefore, another critical function of the database management layer is to maintain consistency in the system's data.
Put another way, the database management layer ensures the meaning of the data it stores. To accomplish this goal, the database management layer must make data available when needed, accept new data only from people allowed to enter changes, and format new data in a consistent fashion. Most important, the design of the database management layer must ensure consistent answers to questions now and in the future. This is the central challenge facing designers who are building client/server databases.
The main tools for building and operating the database management layer are databases, database design tools, and database languages like SQL.
ARE WE THERE YET?
The key to understanding this three-layer architecture is remembering that it is a logical architecture, not a physical one. The very same three-layer application architecture can be used to build distributed systems -- but also centralized systems, too. That's the point: the three-layer application architecture is a better way of building applications -- whether or not they're distributed. However, this architecture will make it easier to distribute application components, if necessary for business reasons. Therefore, the following sections describe how to use the three-layer architecture to build different types of physical systems.
326
![]()
PHYSICAL AND LOGICAL ARCHITECTURES
A physical architecture talks about the physical design of a system. Creating a physical design is the last step before either writing actual code or rushing out to buy hardware. However, a logical architecture is a way of thinking about the broad structure of the application while still leaving lots of choices about how it will be built physically. In designing buildings, a logical design would describe the need for a certain number of bedrooms, a living room, a family room connected to the kitchen, and so on. A physical design, on the other hand, translates the logical design into a precise floor plan complete with dimensions. The whole point of a logical architecture is to capture the broad elements of the overall design while leaving many of the particular choices purposely open.
In the computer world, physical architectures deal with choices about the types of computers installed at particular locations, the actual number of computers required to handle a particular number of users, the type of operating system running each class and type of computer, the amount of disk storage installed at various offices, and so on. The logical design, on the other hand, describes the functions the applications provide to the user, the broad division into layers within the application, and how the major functions within the application relate to each other, all without tying down all the physical options.
Many designers and programmers may look at the three-layer architecture I've just described and conclude that the architecture is physical. It is too easy to draw that conclusion because of the amount of religious controversy about the best way to build client/server systems. The specific problem is that one camp in this religious war is supposed to believe in a three-layer physical architecture. After all, this one camp argues, client/server systems are supposed to have three layers: a work-station, a server, and a mainframe. The problem is that another camp argues just as strongly that having three layers is not required for the construction of effective client/server systems.
The desktop workstation is important; everybody agrees about that. And the database has to reside somewhere; since the mainframe isn't going away, the argument goes, then it can live there. But why bother with an intermediate server? Why not have just a mainframe (as a server, if that sounds better) with lots of workstations connected to it? Of course, nobody would argue against the fact that inexpensive computers acting as servers, sitting between a mainframe and desktop personal computer, offer many advantages in terms of price, performance, and user responsiveness. The question is whether those intermediate servers are really necessary. Die-hard mainframe defenders argue that the intermediate servers, although they do have advantages, are convenient but not required. And because having more computers and more layers introduces more complexity, why not at least consider going back to just two layers? The question these defenders of the status quo will ask about the new three-layer architecture is whether it is really just another way of arguing for servers -- an extra physical layer between the mainframe and the desktop computer.
327
![]()
The critical thing about the architecture I'm talking about is that it favors neither camp. It has nothing to with how many physical boxes and physical layers are finally used to build the running system.
This application architecture has huge advantages in terms of improved development approaches, even if all of the code runs forever on a mainframe with terminals. The architecture we are developing is a better way of designing applications -- whether or not they are implemented in a distributed client/server world.
Computer professionals love to talk about physical topics: what processing should be performed on which computers, which operating system is the best, and what's the best or fastest computer. The question of what should be done where is particularly hot because it raises to a fever pitch all the religious issues about two- versus three-layer physical architectures. For this reason, industry consultants love to portray the what-goes-where controversy in diagrammatic form and, of course, attach fancy names to the alternatives. Figure 11-2 shows a typical what-goes-where diagram. In this figure, M stands for mainframe, S stands for servers, and P stands for desktop workstations and personal computers. Aside from being interesting in itself, the diagram unwittingly proves a key point: the application architecture works well no matter how many physical layers there are.
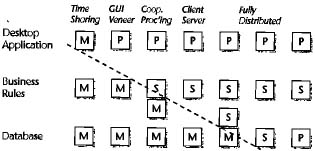
Figure 11.2: A what-goes where diagram with mainframes, servers, and personal computers
When you're looking at some of the columns in this diagram, consider the progression starting at the left:
| The standard mainframe environment implements timesharing; terminals all share the computer time provided by a single central computer. The three layers still make total sense. The software simply runs on a single mainframe. Of course, providing a friendly user interface on a mainframe system would be too expensive. |
328
![]()
| As users become more sophisticated and demanding, it becomes tempting to
implement GUI veneers, which make existing applications look more
attractive. This satisfies users for only a very short time. Even though the
desktop personal computer has now entered the picture, resulting in a
two-layer physical architecture, the logical structure of the application is
still best represented in three layers. | |
| To provide self-managed teams with autonomy and improved performance, an
organization can move some business rule processing onto servers at local
sites. In this case, the company still retains control of the database on
the mainframe at a central location. IBM coined the term cooperative
processing to describe this situation -- where a local and central
computer cooperate to process work. Three physical layers exist at last; the
three logical layers remain constant. | |
| To achieve true client/server processing in a big company, a server
must be able to process local transactions on its own. For example, an A TM
can accept deposits and issue cash withdrawals, even if the mainframe is
down. | |
| Finally, in what some MIS organizations view as the terrifying last step, the database itself becomes distributed, either partially or totally. The mainframe may have disappeared in these last few columns; the physical architecture may have shifted back to two layers (server and desktop); the three-layer application architecture still remains constant. |
So the three-layer architecture is much more than a way of talking about distributed systems. It's also a way of talking about centralized systems, distributed systems, and everything in between. What goes where may be an interesting question; in fact, before a system can be built, that question must ultimately be answered. It is much more important, however, to focus first on the broad logical structure of the application alone. The beauty of the three-layer model is that it works no matter what decisions are made later about what goes where, which physical architecture is best, and how many layers of computers there will be.
Building effective distributed applications runs much deeper than just deciding where things go. Effectively designed applications can be distributed relatively easily. But ineffectively designed applications are virtually impossible to distribute. So focusing on the issue of what goes where -- before you figure out how to build good applications in the first place -- is a mistake of the first order:
| Well-designed applications, built around an appropriate application
architecture, can be split any way you want and need. | |
| Poorly designed applications, without a coherent application architecture, can't be split and probably will never run well in a distributed environment. |
329
![]()
| Poorly designed applications also don't run well in centralized systems. | |
| The key to effective distributed systems is effective application design. | |
| Effectively designed applications will run well in centralized
configurations, distributed configurations, and everything in between. | |
| Deciding where certain layers of the application will run is a secondary
decision. | |
| Using a coherent application architecture is one of the central strategies for designing effective applications and systems. |
Chapter 12 takes the application architecture a step further and shows the first concrete step required to translate that architecture into better applications of all types (mainframe applications and distributed applications, for example). If you build the applications more effectively, then distribution becomes possible. However, if you start out with poorly designed applications, don't even bother trying to distribute them.