The preceding chapter discussed database as a technical and a business concept. I hope that in the process, you understood that the database has been one of the central philosophical forces driving the design of large (and small) information systems for the past 20 years. This concept informs the computing community's view of both why people want computer systems in the first place and how computers should be built to meet those needs. One of the sneaky little complexities surrounding the database concept is that it is not one concept at all. The database concept is actually three things:
| A shared engine providing a shared repository of coordinated, controlled
data | |
| A tool for retrieving, analyzing, and displaying that data | |
| A broader model for representing the state of an organization in both the
short and long term |
The conceptual background provided in Chapter 9 is crucial. If you don't understand the three core database concepts, you won't understand why computers are critical to the future of businesses.
Beyond the core concepts, database also embodies quite a bit of technology, and that's what this chapter is all about. I'll discuss quite a few
260
![]()
technical terms: relational databases, network databases, hierarchical databases, object-oriented tools, query languages, database design techniques, and distributed database technology. These terms -- and more -- come up every time the subject of databases arises. Of course, it's impossible in the course of a single chapter (or even a single book) to completely say all there is to say about databases. It is, however, possible to absorb a relatively complete technical framework for participating in database discussions without acquiring a Ph.D. and without becoming a database programmer. That's what this chapter provides.
Computers will soon change society more than they have at any other time, and databases will play a major role in that revolutionary change. Many computer professionals, however, will readily admit that they barely understand what databases are all about. This lack of knowledge is partly due to the confusion between the three meanings of the word database: shared engine, personal tool, and organizational model. But there's more confusion than just that. For example, if you question a computer professional about his or her views on the issue of relational versus object-oriented databases, you'll quickly discover that nobody seems to have all the answers. The numerous creators of the leading database technologies each claim to impart mystical and magical powers that can be attained only by following the one true path: their own, of course. What's more, these magical approaches are always shrouded in arcane terms that make the average user feel ignorant; that feeling of ignorance leads directly to fear and confusion.
Confusion? Fear? Mystery? Magic? Is this the right book? Surely I can't be talking about computer databases and computer professionals? After all, the computer is the stronghold of the rational, obsessively logical programmer, right? Everything is reducible to ones and zeros, so the story goes; can it be true that these nerds, propeller heads, analysts, and programmers have allowed their safe scientific domain to be invaded by irrationality?
The invasion is real, and it has created some very real problems. The simplest way to understand these problems is to compare the computer world with that other world where analysts are common: the financial world.
According to the stereotype, financial analysts are coldly logical. They live in a world of models, just like programmers. They analyze numbers, charts, and patterns; they create sophisticated financial vehicles. Ironically enough, almost no group of individuals is more susceptible to fads and religions than financial analysts. The reason is simple: accurately understanding and predicting the market is so difficult that nobody can do it, but analysts are evaluated based on their ability to perform this impossible task well. So whenever gurus emerge who appear to offer an approach that can improve predictive performance, everybody rushes to follow their advice.
261
![]()
The stories of financial gurus and their effects on the market are legendary. First, the master has a small following. Some articles and news stories soon follow. New investors, eager for a quick return, beg to have their money managed. Perhaps a newsletter gets published. Television talk shows and infomercials begin to spread the word. Suddenly, every move the prophet makes is magnified by the thousands of imitators and observers world-wide. People begin to wonder if this prophet really did figure out the secret to predicting the future. Finally, it happens: the first big mistake. And two years later, you can't even remember the dethroned king or queen's name, if for no other reason than that you're busy hanging on every word of the next forecaster. Prophets, inexplicable rules and frameworks, donations, mass followings: Am I talking about finances or religion? It's hard to tell the difference.
Software developers have turned out to like, even love, religious movements too. Developing software and building systems that work is difficult. Projects come in late and over budget, and often the completed system is too slow or just doesn't work. The result is unhappy users. Then one day, out of chaos and darkness, the spirit of innovation sweeps over the surface of the waters. It might be new technology or it might be a new way of thinking, but the end result is that everyone jumps on the bandwagon or gets trained to jump on the bandwagon. A new religion is born.
Religion? It's a strong word, but accurate. In 1984, artificial intelligence (AI) was really hot. Supposedly, after years of trying, computer scientists had finally taught computers to learn. By building artificial intelligence into the applications of the future, programming would be eliminated. Software would magically adapt itself to users' needs, and companies would have systems that built themselves -- hardly believable today. But for the next five years, the stock market went wild over AI. Seminars on the topic sold out, and the business press had stories to write. Obscure technologies -- neural nets, rule-based languages, LISP -- were all promoted, and when ordinary computer professionals asked questions, they were pointed in the direction of these unproven tools for the answers. Confused because nobody could explain simply how the new approaches would solve real problems and scared because neural nets, Prolog, and LISP were all genuinely hard to understand, those professionals shrugged and waited.
Recently, the future has been forecast to belong to object-oriented tools. About two years ago, Business Week put a picture of a diaper-clad baby on the magazine's front cover and claimed that object-oriented tools would one day enable infants to build complex systems in days and weeks out of prefabricated components. How will this all work? The answer involves polymorphism, a little SmallTalk, and a dash of encapsulation techniques. It's magic, and if you don't already know the secrets, you obviously never will.
All of these approaches have a grain of truth surrounded by a huge dose of hype. The list of the fads is long enough to be legitimately frightening: structured programming, CASE, AI, object-oriented tools, information engineering, relational databases, object databases, and on and on. Each new fad promises to revolutionize the entire process of building applications. Each draws on some complex and supposedly powerful core
262
![]()
technology that can't be quickly understood. In addition, the proponents of each fad state emphatically that even though the real underpinnings are too complex to understand, if you take the framework on faith, things will get better soon. Maybe.
To confirm the seemingly magical nature of every new fad, skeptics have developed a common name to describe them all: silver bullets. Recall that a silver bullet is the one projectile that can kill a werewolf. Also, in American culture, the Lone Ranger used silver bullets in his trusty six-shooters. A silver bullet is that single powerful technique or technology that will finally provide us with a shining path to better software sooner. Software development is all about religion, silver bullets and all, and that's the problem.
Silver bullets and religious fads represent the voodoo curse that keeps developers and users from a complete understanding of databases. As you'll see later, they also stand between you and a complete und standing of several other important enabling technologies such as design tools, languages, and development approaches in general. To defeat the voodoo curse, you need only rely on common sense.
That's the goal of the remainder of this chapter. You'll explore the technical terms of the database landscape and convert the magical concepts into equally valid commonsense requirements and solutions. By the time you're done, you will develop an understanding of where databases came from, where they are today, and where they're going tomorrow. This understanding will involve precisely the same framework and vocabulary required to deal with the design of future computer systems so that they really meet the needs described in the last chapter.
Recall that one of the roles a database plays is to provide organization-wide shared access to information in a controlled and coordinated fashion. To take an everyday example, when everything in a system works, only one person at a time can reserve a particular videotape, and when a customer makes a reservation, the tape will truly be available. Recall that a database really becomes interesting and powerful at the point at which it starts to deal with many interrelated files all at once.
The first databases -- products such as Total, IDMS, and ADABAS -- were built to support the needs of large transaction-processing applications running on mainframes. A typical transaction always worked with many files at one time. For example, renting a car requires the creation of a rental record that is linked to other records involving an automobile, a rental location, a customer, and a salesperson. This one apparently simple transaction involves five interrelated files. To put this car-rental transaction in perspective, a typical transaction in a branch banking environment requires tracking data in over 20 different files.
When customers walk up to the check out desk at a car rental location, the computer will find their names in one file, the automobile's master record in another file, a credit rating in a third file, the salesperson in another, and so on. This example illustrates one of the central problems that must be solved in designing, building, and using databases: relationships.
263
![]()
To better understand relationships, you have to start by analyzing the first supposedly complex area of database technology: hierarchical and network-oriented databases. These older approaches to database design are reputedly so complex that normal humans will never understand them. Not true, as it turns out.
Hierarchically organized data is very common. For example, an office organizational chart is a way to represent a three-level hierarchy -- in other words, one that goes three levels deep. The president is on top, followed by vice presidents (or other managers), and then everybody else. Of course, this kind of hierarchy could just as easily go 7, 10, or 100 levels deep. (Which is not to say that a hierarchical organization is necessarily as healthy with 100 levels.)
You can also display a hierarchy diagrammatically. Figure 10-1 uses lines and boxes to display the hierarchical relationship among the parts of a car. In this case, the complete hierarchy, all the way down to the individual nuts and bolts, would have many levels, perhaps several dozen. This particular type of hierarchy, called a bill of materials, or BOM, is famous and even infamous in database and mainframe circles because it occurs so commonly and yet is so difficult to deal with. Figure 10-1 is the top part of a bill of materials for a car.

Figure 10-1. A bill of materials displays hierarchical relationships.
264
![]()
Organizational structures, bills of materials, tables of contents for books, project plans, subject classification in a library , agendas for meetings, and many other common collections of data can be represented hierarchically. For this reason, the earliest databases were built to represent hierarchical sets of records.
ISM's first database, IMS, still one of the most heavily used products in large organizations, is designed specifically to handle only hierarchically organized data. Similarly, one of the first products to be marketed by an independent software company was a hierarchical database called Total. Total became not only an important mainframe software product but also the major database for the HP 3000, one of the first business-oriented minicomputers.
Hierarchical databases are not hard to understand at all. They are designed to make it easy to store and retrieve records that can be organized in a strictly hierarchical relationship. A bill of materials, for example, is a snap to represent in a hierarchical database. Similarly, a simple database for customers and orders also is easy. In this case, every customer can have any number of orders, each of which can have any number of specific products, one per line item. Each line item, in turn, may have several shipment records. In the same way, each order may have several invoices and several payments associated with it.
Hierarchical databases are very simple and therefore quite easy to understand, especially if you use them to order information under headings. To understand the limitations of the hierarchical model, you need to develop some tools and concepts for talking about the databases you're building. It's time to move on to data modeling.
Data modeling is one of those scary little terms with a very simple meaning. Just as an architect draws pictures to help clients visualize the house being designed for them, in the same way a database designer draws pictures showing the eventual organization of the information the computer will manage. The architect's pictures are a model of the house; the database designer's pictures are a model of the database. Data modeling, then, is the process of using models, typically in the form of diagrams, to develop and refine the design of an actual database.
Before moving on, I'll warn you that you are getting into an area that many consider the scariest part of the magical kingdom of database, but, as I hope you'll agree in a few pages, it's all very ordinary. I'm talking about entities. Entities are basic types of information stored in databases, typically in a single file or table. They are the fundamental units of data that anybody familiar with an organization would recognize when thinking about how a business works. Customers, orders, products, salespeople, and vendors are all eligible to be entities. Relationships, as you already know, are the connections between the parts (records, tables, files) of a database. Entities are the actual data, classified by type, and the relationships show how these types of data relate to each other. When you describe a database in this way, you are talking about an entity relationship model of that database. What does one of these ERDs, as they're called for short, look like?
265
![]()
The simple four-box diagram in Figure 10-2 is an entity relationship model of a database. The four entities, each in a box, are Sales Region, Salesperson, Customer, and Order. In a simple database, you might take each of these entities and make them into a database file. Your database would have one file with sales region records, one with salesperson records, and so on.
The lines with arrows in Figure 10-2 represent the relationships between the entities. Why do the lines have one-way arrowheads? The arrows are special symbols that mark one-to-many relationships.
| Each sales region has many salespeople, but each salesperson is in only a single region. | |
| Salespeople have many customers, but customers have only a single salesperson. | |
| Customers place many orders, but each order is associated with only one customer. |
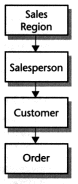
Figure 10-2. A relationship model of a database.
That's it: a simple but complete entity relationship model for a database. Even with this simple model, though, you can make an immediate observation: there's only one way to traverse the lines in this database. That is, given the lines and arrows, you can go from top to bottom only one step at a time, and you can't skip any steps either. Databases with this kind of a design lend themselves to hierarchical representation, and it's easy to see why: a hierarchy looks like a pyramid. Wherever you start in a hierarchy, each item leads to more items below, and when you get to the bottom of a hierarchy, there are no paths back, except for retracing your steps.
266
![]()
Without getting very fancy at all, Figure 10-3 adds Market Segment (for example, a bank, manufacturing company, and so on) and Products to the model. Six entities instead of four isn't much difference; it's the relationship that's really different in the new diagram. When a relationship has arrowheads at both ends, it represents a many-to-many relationship.
| Each order can have many products in it. | |
| Each product can be part of many orders. |
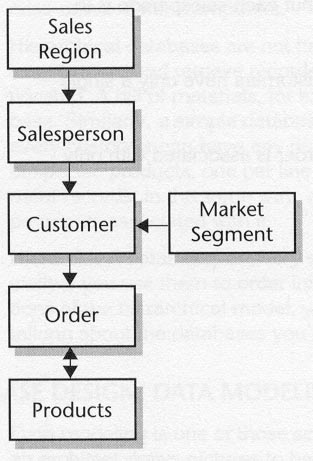
Figure 10-3. The database model with some new relationships.
The addition of Market Segment and the presence of the many-to-many relationship between Order and Products create real problems for hierarchical databases. To really see why, you need to think of hierarchical storage using a mechanical analogy -- filing cabinets.
A hierarchical database can be thought of as being like an electronic file cabinet. To organize information, the first level in the hierarchy corresponds to hanging file folders, the second level to individual file folders sitting inside a hanging folder, and the third level is equivalent to individual records, documents, or forms sitting inside each folder . If the hierarchy has four levels, then the top level can be a file drawer with hanging folders in each drawer. You can even get to five levels by making entire file cabinets serve as the top level. For example, you can have a cabinet for each sales region, a drawer for each sales office, hanging folders for salespeople, individual file folders for
267
![]()
customers, and paper forms for orders. The bottom level in a paper-based system often corresponds to lines on a single page. In this example, the fifth level represents an order form, and the sixth level represents specific line items for particular products on an order form. The beauty of a hierarchical database in a computer is that you can work with hundreds of levels if you need to.
Imagine now that you've actually stored the database in the diagram in a set of filing cabinets organized by sales region, salesperson, order, and product. Management suddenly asks for a report showing sales by region. The filing system supports the generation of this report very well. You work through the drawers, hanging folders, folders, and orders, one by one, and keep running totals as you go along. Soon you have a report. Suppose that next, management decides that it wants the same report showing sales by market segment.
Generating a report based on market segment is a nightmare given the hierarchical organization by sales region. You'd like to start with, say, sales to banks, and then look at manufacturing companies, then airlines, and so on. Banks, however, are scattered all around the world. Lots of your salespeople have banks as customers, but your files are sorted by region, not by market segment. The orders for banks are therefore scattered all through your cabinets, hanging folders, individual folders, and orders. This is a report you simply can't do any time soon. You can reorganize the filing system so that all the records are grouped by customer type in order to produce the second report, but then you won't be able to produce the first report anymore. To make matters worse, management wants both reports and a new report showing sales by product type as well. A third way of organizing the data? How can you ever do that in a hierarchical database? You can't. You need a more general form of database.
About five years after the concept of databases first became popular, designers realized that many users required a more general database model that preserved the conceptual simplicity of the hierarchical approach while adding the flexibility to deal with many hierarchies at one time. The result was the development of network databases. The term network in this context has nothing to do with LANs, WANs, terminals, or any other communication technology. In fact, I'm talking about yet another meaning and use for that overused word.
One more time, here's the dictionary definition of network:
268
![]()
In this case, I want to focus on the second definition -- something resembling a net in consisting of a number of parts, passages, lines, or routes that cross, branch out, or interconnect.
Figure 10-4 shows how this definition relates to the example. In the center of the figure is an order for 500 brake pads. This order of 500 brake pads is a record in the order database, which is part of the order entity in the database model. At the top of the picture, you see the Regional hierarchy. In this hierarchy, the order is related to the single salesperson who placed the order. It belongs in a single file folder in that hierarchical storage system. At the right is the Market Segment hierarchy, in which the order belongs in a completely different file folder corresponding to the type of company that placed the order. Finally, at the bottom is the Product hierarchy. In that organizational system, this same order belongs in a folder with all other orders for brake pads, which are in a bigger order for brake parts in general, which is in a drawer dealing with suspension components, and so on.
In a hierarchical database, whether manual or computerized, each record lives in only a single folder. The relationship among all of the records in the database can be drawn as a single hierarchical diagram (such as the ones in Figures 10-2 or 10-3).
A network database allows records to be in multiple folders all at the same time. The diagram for a network database shows individual records with many lines connecting those records to other records. In a hierarchical database, each record is related to a single parent record sitting above it in the hierarchy. In a network database, any record may be related to any other record.
If you were playing connect-the-dots, hierarchical databases would force you to follow very strict rules. Network databases, on the other hand, allow you to have any rules you want in terms of which dots can be connected to which.
Conceptually, a network database allows you to arrange the data into any number of hierarchical views, all at the same time. The sample order for 500 brake pads can be viewed in a network database as part of a regional hierarchy, part of a product hierarchy, and part of a market segment hierarchy. If the network database were a filing cabinet, it would be a filing cabinet that could magically and instantly rearrange all of its folders at the command of the user. Come at it one way and the drawers are regions; the hangers, salespeople; the folders, companies; and the forms, orders. Press a button and suddenly each drawer is a market segment with folders and forms rearranged accordingly.
Why call it a network database? Going back to the definition of network, when you draw a picture of the records and the relationships between them, the result looks like a network. The lines connecting all the records cross, branch out, and interconnect to form an openwork fabric or structure.
269
![]()
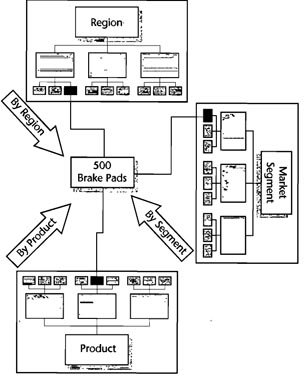
Figure 10-4. Entities interconnecting around an order.
What kinds of applications really need the flexibility of a network? A quick look at the data model (recall Figure 10-3) tells the answer: any entity with more than one arrow approaching it implies multiple hierarchies, which in turn calls for a network database representation. Both Customer and Order entities meet this requirement. Salesperson and Market Segment point to Customer, and both Products and Customer point to Order.
Each arrow tells us that the records in a file are the children of the records in the other file the arrow came from. If two arrows point to a file, each of the records in that file can have two parents. Therefore, no single hierarchy will be enough to answer all questions about a database with arrows going in more than one direction, and a network is required to allow multiple hierarchies. If this is a little hard to keep straight, go back to the example and chase it through a couple of times.
270
![]()
Finally, recall that when I first introduced this particular diagram as an example, I pointed out both the two arrows coming into Customer and the double-headed arrow between Order and Products (see Figure 10-3). Relationships with arrows at both ends always imply a need for network representations. Why? Because each file is the hierarchical parent of the other. For example, even if the diagram contained only Order and Products, no single hierarchy would be enough. After all, the two arrow-heads indicate the ability to make the following request:
| Show me all orders sorted by product. | |
| Show me all products sorted by order size. |
Of course, you can handle a database as simple as this one in lots of different ways. Nobody would invent network databases just to provide two different sort orders. The important point is that there are simple clues you can find in a data model that tip off the best way to think about a database and its implementation. And when databases become more complex, network representations become important, even critical. It's now time to consider a more complex database.
Network databases are definitely more complex than hierarchical databases. In a hierarchy, there are only two directions to move from any record: up or down. In a network, there are many choices. This complexity can represent either a challenge or an opportunity. As it turns out, for the last 15 years, network structures have been viewed as a liability when in fact they are much more of an opportunity. The result has been a 15-year argument over the merits of network databases, database navigation, relational databases, and the more recent object databases and the navigational facilities they bring back from the past. To see what I'm talking about, consider a more complete and familiar example.
Even a chain of video stores requires a relatively complex data model, as shown in Figure 10-5. With a few examples just to help you start, try navigating your way through this data model.
| Customers rent videotapes and/or laser discs, each of which is checked out
by a single salesperson. Each salesperson, of course, checks out many
customers. | |
| Laser discs and videotapes, each associated with a single movie, may be
acquired from several distributors and are located at several stores. | |
| Each movie may be available in laser disc or videotape format, and there may be several copies at each of several stores. Each movie is made by a single producer but may have many movie stars in it. |
271
![]()
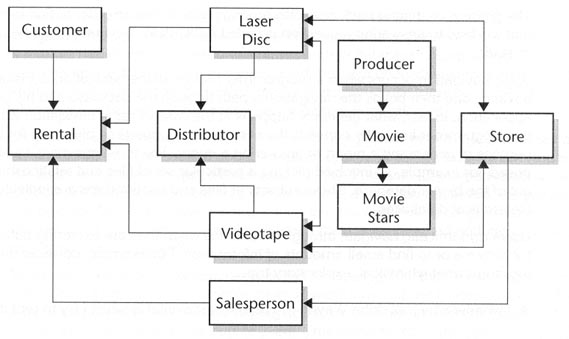
Figure 10-5. A complex data model.
To begin to understand this simple database, you'll have to steer through several boxes and lines. This exercise is sometimes referred to as database navigation. Navigation is only mildly interesting when just looking at the database; it becomes essential when it comes time to answer questions based on the records themselves:
| Which movies are the most popular? T o answer this question, you
have to look at rental records. The rental records, though, refer to
particular copies of videotapes, probably by serial number. The serial
number takes us to the inventory record for the copy of the videotape (or
laser disc), which in turn points back to the movie title. To answer this
question, you had to navigate through four sets of files (rentals,
videotapes, laser discs, movies) using records in al1 four. | |
| Which stars are the most popular? You'll need to maneuver through
five files this time. Besides all the files that you've already used, you
also have to get back to the database file that lists the stars by movie. | |
| Who is the most popular star in New York City? At this point, you're using six files altogether. The problem is that the rental records don't tell you what city the customer lives in. You could go back to the customer file or, more directly, use the store file that lists the location of each store. |
272
![]()
The process of shifting back and forth among multiple files in order to find information that will lead to answering a question is called navigation. Navigation can be dynamic or static.
Static navigation occurs when a programmer makes all the navigation decisions in advance and then builds the navigational path through the database into his or her application. In fact, what generally happens in the case of static navigation is that the programmer implicitly converts the network into a one-time hierarchy for the purpose of generating a report or answering a query. The three questions I just posed, for example, all involved picking a particular set of files and relationships out of the bigger database. These subsets of files and relationships are individual hierarchical databases.
Users dynamically navigate through a database when they are exploring data to look for patterns or to find small amounts of information. For example, consider the following, somewhat whimsical, exploratory trip:
| I wonder why that John Wayne movie is never available when I try to rent
it? | |
| Start by seeing what movies John Wayne is in to be sure I have the title
right. Ah, there it is. | |
| Now, how many copies are available at the store I go to? Two copies. Seems
strange that it would never be in. Check to see how often it gets checked
out. | |
| One copy was lost quite some time ago and one more recently. But I recall
having trouble with other John Wayne titles. Are they somehow lost too? | |
| That's strange. All the John Wayne titles seem to be gone. What about
other similar movies? No, they're not lost. I wonder who checked those Wayne
movies out? | |
| That's it! There's a closet John Wayne movie thief at this particular store, and I've found him. This customer obviously loves Wayne movies so much that he or she borrows them and never returns them. |
Tracing a path back and forth through all the files, records, and relationships to discover why a particular set of movies wasn't available would present an interesting picture. You could think of the database as an information space of interrelated data, the relationships as paths from data file to data file, and users as navigators discovering new facts as they travel through this database world.
In 1973, Charles Bachman, one of the pioneers of database technology, received the Turing Award, the computer industry equivalent of the Nobel prize. On the occasion of receiving the award, he presented a now famous paper entitled The Programmer As
273
![]()
Navigator. For the first time in a published paper, Bachman introduced the idea of navigating through a sea of data with exciting computer applications that allow users to explore the information resources buried in their databases. Surprisingly, 20 years later, this concept is not only misunderstood, but also often viewed as somehow either wrong or bad. And yet Bachman's concept of database use turns out to be fundamental to what users really want as they become more sophisticated.
Early databases were all built with the needs of programmers in mind.
Databases and terminals became common at about the same time, and at first,
nobody anticipated that users would want to query databases directly.
Professional programmers wrote applications that used databases. If a user
needed a question answered, the programmer built the facility to answer that
question into the application program. Users with unusual or ad hoc questions
simply assumed that computers had nothing to do with answering those questions.
As terminals became common, users began wondering why they couldn't get
information out of the computer in some more general way without having to
constantly depend on programming changes in big applications. That wonderment
changed quickly into a demand on the part of users. This demand led to the
development of report writer and query technology. In fact, the first software
product to achieve over a million dollars in sales in its first year was a
report writer produced by a company called Pansophic Systems. Its product, still
aimed at programmers, allowed ad hoc reports to be produced in hours instead of
in days. For the first time, programmers could be responsive to the needs of
users. Pansophic advertised its product with a simple and evocative image of a
skeleton sitting at a terminal, festooned with cobwebs, with the single tag
line: "Tired of Waiting for Reports?" Thousands of users were tired,
and Pansophic's sales took off. But in the end, even faster reports weren't
enough to satisfy users.
Users want to be able to ask questions on the fly, get answers right away, and then decide what question to ask next. Sometimes the answer to the question will be a lengthy report; other times it will be just a few lines of data. Either way, all users want their data immediately, and they want to be able to ask for it without depending on technical professionals.
Hierarchical databases have fundamental problems servicing this type of need. IMS, Total, and all the other hierarchical products enforce a single hierarchical view of the data. As you've seen, even in relatively simple situations, many types of questions lead to hierarchical views that are different from the one the designer chose. Putting this another way, limiting the data representation to a single hierarchy virtually guarantees that the chosen hierarchy will be the wrong one for most users.
By the time Bachman presented his paper, though, the successor to hierarchical databases, the network database had been invented. Products like IDMS, IDS, and others allowed networked data models to be represented directly in the structure of the database. In a hierarchical database, each record has at most one parent, and that record may have many children. A network database essentially allows a record to be related to an unlimited number of other records. An order record can be related to a product
274
![]()
record, a customer record, a shipping record, an accounting record, and so on. Net-work databases allow each user to take his or her own hierarchical ( or even nonhierarchical) view of the data. They are called network databases precisely because the web of relationships looks like a net or network of lines.
What kinds of queries can be answered easily with a network database? All kinds. That's just the point. Because a network database can represent directly all the kinds of relationships inherent in the organization's data, that data can be navigated, explored, and queried in all kinds of interesting and powerful ways. That's why the original idea expressed by Bachman is such an exciting one. Why then did network databases gain such a bad reputation, and why were they replaced in popularity by relational technology?
Compared to hierarchical systems, network databases were a big step forward, but database technology in the early 1970s was still very immature overall. No standards existed; tools and utilities were mostly nonexistent; even experts were still figuring out what database design was all about. On the one hand, network databases quickly became quite popular among the mainframe crowd and even went on to become the basis for the first database standard, promulgated by the Conference on Data Systems Languages, or CODASYL. On the other hand, in spite of the continued advances in technology, all kinds of databases were very hard to use.
To gain a perspective on how difficult to use databases were, think about any computer technology of 10 or 20 years ago. Word processors, for example, were far harder to use than those that have spoiled us today. Most people didn't use word processors: they were too expensive, too limited, and certainly far too hard for ordinary people to use. Twenty years ago, databases and query processors were even worse.
Although network databases had the potential for facilitating flexible, powerful, and adaptable queries, the query software itself more than negated any possible advantage of the underlying database by making the whole process complex, hard to learn, and generally useless for ordinary users. In this context, network databases made things worse, not better, than simpler alternatives.
When databases were first invented, it was assumed that the only people who would use them directly would be database programmers who were highly familiar with both the database technology and the detailed design of any particular database they were working with. As a result, diagrams like the data models were considered standard working tools by all users of early databases, most of whom were programmers.
Given this background, imagine the approach the designers of the early query tools took: they assumed that their users would be just like database programmers. They therefore assumed that before users would ever ask a question, they would first have a map of the complete database and develop their own strategy for navigating through it. What's more, the picture of a real-world database is bigger and far more complex than the diagrams I've presented. Imagine the reaction of typical users, never exposed to a computer, who were asked to learn a complex query tool with a completely non-graphical interface, a tool they couldn't even use until they had understood the structure of the database completely and developed a navigational strategy to go with it! Nonstarters? You bet.
275
![]()
In the midst of this database development of the 1970s, Edgar Codd, an IBM researcher, began working on a new database model called the relational model. With a name like that, you might think that this model was particularly adept at dealing with relationships between files. In fact, quite the opposite. This misconception is just one of several many people have about the strengths and weaknesses of relational technology.
In mathematics, a relation is an unordered set of n-tuples. Huh? An n-tuple is just a set of n different values, what you would call a record. A relation is close to what you would call a file. As you may have already noticed, the discourse is getting a little muddy in a couple of significant ways.
The first, which is sneaky and slightly unfair, but not insidious, is the renaming of words. The first thing you have to quickly get used to is that in the relational world, files are tables, records are rows, and fields are columns. Other than forcing users to learn new vocabulary, these word shifts don't create any real problems. Codd correctly observed that although the big corporate database required complex sets of files with rich sets of permanent relationship links, most users who ask questions and explore data live in a much simpler world. In fact, most of them think not of files, records, and fields, but of tables, rows, and columns. Users are far more comfortable working with simple collections of tables than with complex sets of files and relationships. By making this observation, Codd prefigured the invention of the spreadsheet by several years.
The other problem of discourse lies in the name of the technology itself: relational databases. Paradoxically, relational systems don't handle relationships directly. Later in this chapter, I'll return to this topic to explore how a database can be called relational without representing relationships per se.
Moving away from explaining vocabulary, relational databases, unlike network and hierarchical databases, make it very easy to establish relationships between previously unrelated files on the fly. Working with a relational database, a programmer or a user can quickly and easily define a new relationship between any two tables. Relationships can even be defined between tables with no previously defined relationship. With network databases, relationships must be predefined before users can access them. Relational databases don't have this problem, and that's what makes relational systems so popular. In order to perform this little trick, relational systems introduced a new idea to the world.
From the beginning, every relational database came complete with a query language. That language, SQL (structured query language), became an intrinsic part of the database. Today, it is commonplace to simply assume that SQL and databases are inseparable. In the 1970s, though, there was a sharp separation between databases and query languages. Narrowly defined, a database is simply an engine for managing
276
![]()
shared data, and a query language is a specific tool for specifying sets of records to be retrieved from a database. Ideally, every database can be accessed through many query tools, and a query tool can work with many databases.
What do I mean by query language? For starters, a language is an agreed-on set of words, grammatical rules, and so on that allows people to communicate with each other. Computer languages, like human languages, consist of sets of words, symbols, and grammatical rules that allow humans to communicate with computers. Computer languages exist for the benefit of people, not computers. Although it is commonly assumed that computer languages -- for example, COBOL, FORTRAN, Basic, and SQL -- are designed for computers, they are not. In reality, they're designed to make it easy for people to tell computers what to do.
In the 1970s, as Codd was developing his relational database theory , he concluded that one of the most basic purposes for databases was the facilitation of question asking. Codd wanted relational databases to make it easy for users to find data in them. If people are going to ask the database to find some records, he reasoned, these people need a language that will make it easy to ask for those records. And that's how SQL was born.
There is a broad perception, particularly among computer-literate professions, that SQL was the subject of careful and painstaking design. After all, the relational model with which SQL is so closely associated is believed to be one of the few parts of any computer system that is supposedly firmly grounded in a sophisticated mathematical model. People assumed that if relational databases were theoretically sound, SQL must be at least as well crafted. Not true, but don't read this paragraph the wrong way: SQL has many positive attributes. It is the most widely used database language in the world and has stood the test of time. At the same time, though, SQL in many ways shows its heritage, and that heritage is one of accidental birth. Yes, that's right: accidental birth.
In the 1970s, as Codd was starting to build prototypes of relational databases, he and his colleagues quickly discovered the need for a query language that could be used to work with the data in the engines they were building. As a pragmatic vehicle to allow their research to proceed, they designed what they originally called structured query language. As it turned out, SQL was first developed at a time when good query languages simply didn't exist. So along with the relational technology underneath it, SQL filled a vacuum, and as a result, it quickly became a standard.
Why does this matter? First, understanding the true background behind relational databases is essential to penetrating the mythology surrounding them. Second, after about ten years, a strange thing happened to both relational systems and SQL. The religious movement developing around SQL became formal -- an unusual occurrence even for the often bizarre computer world. I'll discuss this formality later in this chapter.
277
![]()
So relational systems (RDBMS as a quick abbreviation for Relational Database Management Systems, or simply RDB) are tightly coupled to a query language called SQL. What's that got to do with network databases and ad hoc relationships? SQL makes it easy to specify ad hoc relationships between files or tables on the fly. In fact, SQL's capability to perform this task is based on an underlying high-level operation in the RDB -- a join. As you'll see, however, it is not just the join that made RDBs popular. Rather, it was the fact that this powerful capability was made so accessible through the query language.
High-level operations such as joins are instructions that allow a person to tell a computer to do a whole bunch of work all in one request. A spreadsheet provides high-level operations to sort hundreds of rows, produce complex graphs, and change the formatting of an entire spreadsheet. Word processors provide high-level operations for reformatting documents, producing tables of contents, and converting documents into multicolumn formats. The key idea here is simple: provide users with tools that allow them to ask the computer to carry out high-level operations that work on large amounts of data all in one step -- without any programming.
A join is a high-level operation that combines two previously unrelated tables into a single bigger table. For example, a table with biographical records for movie stars can be joined to another table listing movies. The joined table contains both the data for each movie (for example, title, length, producer) and the biographical data for each movie star in each movie (height, weight, birth date, current lovers, and so on).
Codd was one of the first computer pioneers to realize the importance of high-level operations. In the relational world, these are usually called set operations because they work with entire sets of records all in one step. The point is that high-level operations provide the user with a vocabulary for working with large amounts of information without programming. With high-level operations, the power to manipulate quantities of data is not only in the hands of programmers, but also in the hands of ordinary mortals.
So relational databases contained two breakthroughs, both of which relate to working with files and records. First, they introduced a set of high-level operations such as joins that allow users to manipulate entire databases by using a small number of powerful tools. Second, Codd and his team made these operations available directly to users through a somewhat English-like language called SQL. It is that combination that has made RDBs popular ever since.
What about SQL? Who is it for? Is it really easy to use? How does it compare to other query languages, and why is it so dominant?
What's so great about SQL? Compared to other technical languages like COBOL, C, or even Basic, SQL is relatively straightforward. To begin with, it has a far more limited objective. Unlike a conventional programming language, the mission of SQL is limited to expressing queries.
278
![]()
A query is a specification that allows a database to retrieve a specific set of records. Some examples are
| All movies with John Wayne in them | |
| All bills outstanding more than 30 days | |
| All Japanese cars owned by Scandinavian engineers living in California with incomes over $50,000 who have ordered from a certain catalog more than six times during the last three years |
Queries may be simple, like the first two in the list, or very complex, like the last one. In addition to specifying a particular set of records, a query may also manipulate those records as a set:
| List all salesmen who are over 105 percent of quota and compute the
average and total sales for all those salesmen by product line and by sales
territory | |
| Retroactively increase salaries by 10 percent for all interior designers
in Connecticut who have been with the company for more than three years | |
| Forget about (delete) all bills that have been outstanding for more than one year |
The purpose of a query language is to allow all of these kinds of queries and more to be expressed so that a computer can find sets of records, make changes to them (specified in the query), and then make that changed set of records available for more queries.
SQL is a powerful language. A wide variety of sophisticated queries can be expressed effectively in the language. Query engines have been built that efficiently retrieve and manipulate sets of records based on SQL queries. So in terms of providing a powerful, high-level query language for computer professionals, SQL is an unqualified success.
SQL provides an English-like language for specifying queries. At the time it was designed, one of the goals was to make it possible for any computer user to learn SQL. In fact, one of the reasons for designing SQL was to allow Codd and his colleagues to learn whether a query language could be made easy to learn and use. Besides being somewhat ad hoc, SQL was also experimental. It was a considered an early experiment in ease of use. After almost two decades, the verdict is in.
SQL isn't for everyone. SQL is a powerful and dominant language, but it is too complex for most noncomputer professionals to ever learn. Contrary to the fondly proposed idea of the 1970s, not everyone will one day learn SQL. Although SQL is simpler than a language like C, it is still as far beyond the understanding of most computer users as the detailed operation of the internal combustion engine is beyond most drivers. Most drivers will never learn to adjust valve timing on their cars, and similarly, most computer users will never learn or use SQL directly. As it turns out, whether you
279
![]()
learn it or not really doesn't matter.
Although people may never talk SQL, database tools talk it. Products such as Paradox, dBASE, Access, and dozens of others provide users with graphical mechanisms for specifying queries, viewing sets of records, and causing changes to the underlying data. These software tools speak SQL on the user's behalf. Although Codd's original intention in developing SQL was to empower end users directly, the use of SQL in applications has empowered end users even more than if the language were directly useable.
Earlier in this chapter, I asserted that database has three different meanings. SQL turns out to be a lingua franca providing a universal bridge between two sides of the database world. On the one side is the database engine. Many different software vendors have built different database engines designed to serve a variety of specialized needs. On the other side, literally hundreds of end user database tools focus on user interface, analysis, and presentation. Without SQL, there would be no easy way for all the different front-end tools to talk to the many database engines. Because SQL has become the standard, users can take it for granted that when they have chosen a personal database tool, they will then be able to use that tool to retrieve information from all the different database engines in which that data may be stored.
First you looked at hierarchical and network databases. You then started to explore the relational model, which introduced the idea of tables as a simpler way of thinking about files and records. After a side trip to learn about joins and high-level and set-oriented operations, I introduced SQL as a query language that was originally designed for people to talk to programs. As you've just seen, SQL turns out to be most useful as a language for programs to talk to other programs. Having taken you this far, I now have to dive a little deeper into databases. Specifically, you are now in a position to gain a complete understanding of tables, joins, relations, and the relational model.
The network model is built around the idea of expressing the structure of the organization's data directly in the design of the database itself. This shows up in two ways:
1. Records have a relatively complex structure in network databases:
| An order record contains both the header information specifying the
customer's name and address and all the individual line items describing
specific products, quantities, and costs. | |
| An employee record contains both the employee's own personnel data and the
records for each of the employee's dependents. | |
| The record for a low-level part may contain both the specifications for that part and for all the subparts (components) that make it up. |
280
![]()
2. Relationships between files are built directly into the database at the time that it's designed.
Both of these characteristics come down to the same thing: the explicit representation of relationships in a network database. Complex record structures encode detailed relationships, and interfile linkages express the higher-level relationships. Relational databases, despite the name, are based on the assumption that these relationships should not be wired into the database at all. Instead, so relational theory goes, the database and its query language should provide powerful tools, like the join operation, that allow relationships to be specified and acted upon on the fly. Going even further, the relational model calls for the structure of both the database and the records to reflect the idea of not building relationships into the database itself.
At first, this idea might sound crazy. Databases are all about relationships, so if you don't build them in, aren't you unbuilding the very thing you set out to build in the first place? Perhaps not. It's time to explore why relational proponents believe that their model is better.
The reason for not building relationships in is simple: flexibility. Also, the choice of not building relationships can lead to additional simplicity, but only sometimes. Hierarchical databases are limited because they force the choice of a single hierarchy. Network databases, no matter how many built-in relationships they have, are still limited because there will always be more relationships that users will want to create and use. The relational model solves these problems completely by allowing any two sets of data to be potentially linked through a relationship created on the fly.
To work its magic, a relational database depends on three principles: normalization, foreign keys, and joins. Before I explain these concepts, a word of motivation is in order. This chapter is somewhat technical. The next few sections are the most technical (but still understandable) parts of an already technical chapter. You need to know the upcoming information, though, because it come up all the time when relational databases are discussed. By spending just a small amount of time on these topics, you can learn enough to at least understand the context of RDB conversations. More important, with just three tricky concepts under your belt, you can really talk about the future of databases in a fairly complete fashion.
Normalization is the database technique for eliminating complex record structures, and foreign keys is the corresponding technique for dealing with interfile relationships. Between the two of them, these two techniques get rid of all directly expressed relationships. Joins, in turn, provide a mechanism for putting the relationships back by constructing them on the fly. Having provided that overview, I'll go into more detail.
When considered in detail, normalization is a complex topic, the subject of many books and papers. What I will do here is develop the concept and leave the details to computer science courses and textbooks. The simplest way to understand normalization is through an example.
A video store database has three different files dealing with people: customers,
281
![]()
employees, and movie stars. A goal of any database is to completely eliminate redundancy so that any piece of information is stored in exactly and only one location in the database. The problem with the current structure of the video database is that information about individuals is stored in not one, but three places. An employee who is also a customer would have two records containing his or her name and address. If that employee was also a movie star (a stretch, I know), his or her name and birthdate would be in three places in the database. As you've already seen, this redundancy makes it a problem to keep data up-to-date in three locations. More important, this redundancy produces consistency errors in reports (remember the irate company president?). How does the relational model solve this problem? Through normalization.
As Figure 10-6 shows, you can normalize the people-related parts of the database by creating an additional and separate file just to store information about people. Part of normalization involves splitting out data that occurs in several files and putting it all in a common place. Besides eliminating redundancy, this technique creates a new design improvement: if you want to know about a person, there's a single starting place that will always contain the data about that person. As it turns out, this simplicity is an even bigger advantage than you might expect. To show you what I mean, consider another example of normalization.
Both the video store database and the earlier customers, orders, and products database contained a file for recording business transactions: rentals for videos and orders for products. In both cases, a non-normalized design places several product orders or rentals in a single record. Certainly this is the way it's done on paper. However, this design does create a problem when it comes to asking questions:
| The video database makes it easy to find all videos checked out by a
single customer because that's how they're grouped. If this database were a
hierarchy, the bottom level would be the rental form listing several
videotapes. All forms are stuck into a customer folder, and all the folders
are organized by store. What if you just want to find all the rentals of
John Wayne movies? The hierarchical system forces you to read every rental
record, one by one, in order to find John Wayne movie rentals. | |
| The orders database makes it easy to find orders placed by a particular
customer. What if you want to find all orders for a particular product?
Again, you have to read through all the order records, examine line items
one by one, and pull out those items associated with the products you're
interested in. |
This sounds like the very flexibility problem inherent in hierarchical databases. Normalization is the final step required to make the lack of flexibility problem go away. The solution to both of these particular problems is the same: split the repetitive data -- the multiple rentals and the multiple line items -- out into a separate database.
282
![]()
In the normalized diagram (Figure 10-6), rentals of individual videotapes are collected in their own file. one record per videotape rental. In the same way, the new customers, products, and orders database (see Figure 10- 7) has a separate file for line items. Conceptually. normalization is the process of taking all repetitive data that appears in more than one place and splitting it into separate files. The net effect of normalization is to eliminate all complex records from a database:
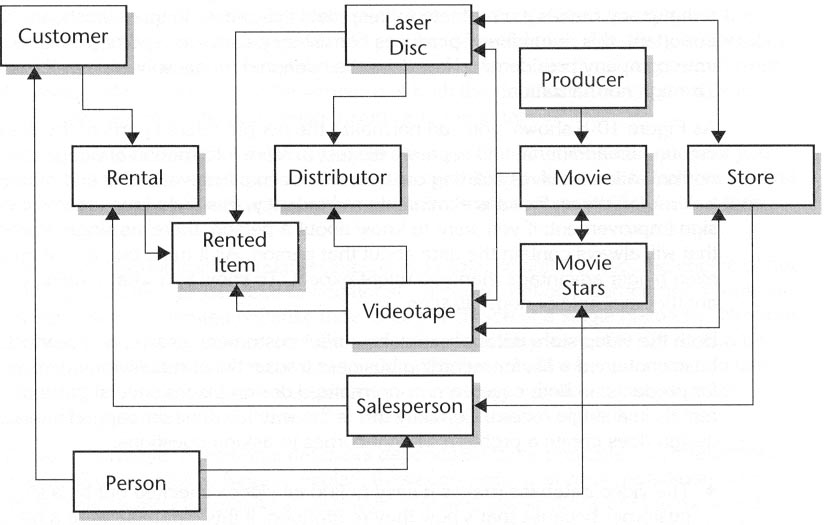
Figure 10-6. Normalizing the people-related parts of the database.
| Orders are stored in two simple files: the order header containing the
customer's name and address and the line-item file containing individual
records with a single line item each. | |
| Employees are now represented in several files. The employee's own
personal data is in a single record. In addition, simple individual records
are used to describe each of the employee's dependents: one record for each
child, one for the spouse, and so on. | |
| Products, assemblies, parts, and components are all described in simple records. If a part is made from subparts, one record describes the main part, and each subpart is described in its own record. |
283
![]()
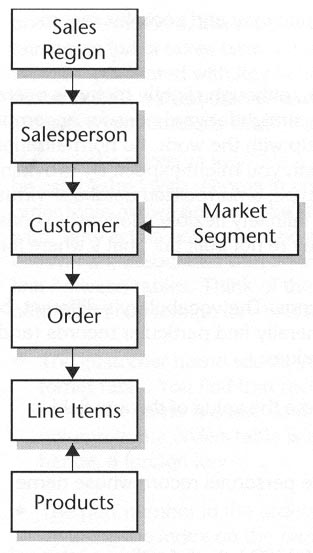
Figure 10-7. The customers, products, and orders database.
A fundamental tenet of the relational model is the use of simple tables to replace complex records. A record historically has stood for a complex structure:
| Records may vary in length: some employees have children; some don't. | |
| Records contain repetitive subrecords: line items, subparts, dependents. |
A file composed of records can be a relatively complex structure. On the other hand, people visualize a table as a simple structure composed of rows, each with a fixed number of columns. Spreadsheets are so popular as databases because simple tabular structures are so easy to understand and work with. By definition, a relational data- base built around a simple (and limited) tabular structure not just encourages but also requires that data be normalized. Complex record structures cannot be stored directly in a relational database, so normalization is the only route through which data can be put into an RDB.
At this point, I can give you the first of three rules in the relational approach to relationships:
284
![]()
| Normalize all database designs so that redundancy and complex record structures are eliminated. |
In passing, it's worth saying that normalization, although slightly tricky, is overall a very mechanical process. There are relatively straightforward rules for accomplishing the process and computer-based tools can help with the work. So normalization, even if it sounds scary, is a much easier process than you might expect. By providing a single place to find all records of a particular type, a normalized database virtually eliminates redundancy while allowing almost infinitely flexible relationship construction. How do these relationships get built if they're not built in? That's where foreign keys come in.
Records have fields; rows in tables have columns. The vocabulary's different, but the concepts are the same. The way that you generally find particular records (and rows) is by searching for particular field (column) values:
| All records for people over 30; records where the value of the age field
is greater than 30 | |
| George Washington's personnel record; the personnel record whose name
field has the value George Washington | |
| The record for the part with serial number 94387 A; look for the serial number field with the value 94387 A |
Finding records very quickly based on the value of one or two key fields is a common and critical operation in every database. For this reason, special facilities are built in to make these retrievals essentially instantaneous. A database will typically build and maintain an index: on the fields that will be used for retrieval. Books have indexes that allow the reader to quickly find out what pages contain references to certain words and topics. Imagine trying to find discussions about joins in this book if there were no index. It would be quite difficult. A telephone book is just a huge index that allows you to find the phone numbers of people whose names you know. Finding a name if you know only the phone number is so hard that you wouldn't even try unless you have access to the phone company's reverse index, which lists phone numbers in numerical order along with the phone subscriber's name. Indexes make the difficult task of finding information almost trivial, and indexes are fundamental to databases.
An index provides a key to the data that otherwise would be locked up in the database. For this reason, indexed fields are generally called key fields or key columns. A table or file may have many key fields or no key fields (in which case records can be found only by searching through the file one record at a time). For example, a customer table may be indexed on customer name, customer number, city, and sales region. If indexes are so handy, why not just index every field? Some databases do this automatically, and most databases provide the flexibility to make indexing all fields possible. However, indexes carry with them a significant drawback. In the first place, the index takes up space on the disk. If every occurrence of every word in a
285
![]()
book were indexed, the index would be almost as big as the book itself. Also, maintaining an index takes time. Each time a record is created, changed, or deleted, all the indexes associated with key fields have to be changed as well. Adding too many indexes makes a database run slowly. Too few indexes make retrievals slow; too many indexes make changes slow -- just another trade-off designers must deal with.
Now what's a foreign key? It's a column added to a table that allows a relationship to be established with records in another table. Having a customer name column in an order table allows orders to be linked to the customer records they are associated with. Why is this column called a foreign key? Because the values in a foreign key column are associated with an index built on another table. A foreign key unlocks the link between tables. Think of the advantages of having, for example, an order record containing two foreign key fields: customer name and part number.
| The customer name allows you to look up the customer record in the
customer table. You find that record quickly by relying on the fact that the
customer name is a key field in the customer table. The customer name column
in the orders table is a key field that is indexed in the customer
table; hence, a foreign key. | |
| The part number in the orders table allows you to quickly look up part records by using the index on the parts table. Again, you have a field that is keyed to an index on another table. |
Why are foreign keys so special? The answer is at the heart of the relational model. Network and hierarchical databases maintain relationships by using invisible pointers. A pointer is simply a field that points to another record, often in another file or table. For example, an order record could point to all the parts in an order. The problem with network and hierarchical databases is that you can't always see the pointers directly. This is a critical, if somewhat subtle, point that requires more explanation.
Suppose that you're looking at a printed report listing customers, their
outstanding orders, and the parts associated with each order. Perhaps the report
looks like this:
| Acme Kennels | May 13,1993 | Dog Food | $425.13 |
| Cat Food | 65.19 | ||
| Hamster Food | 1,119.25 | ||
| May 1,1993 | Giraffe Food | $352.17 | |
| Canine Carnival | May 15,1993 | Flaming Hoops | $459.13 |
| Jumping Fleas | 25.00 |
How did the database know that the customer record for Canine Carnival had any orders associated with it? The answer is that there is a pointer making the connection, but what does that mean? In a database, one way or another, every record has, or ought to have, at least one unique key associated with it, a key value that allows users to always refer to that record and only that record. This is often called the primary
286
![]()
key. A customer number is a good primary key because it generally refers to one and only one customer. In fact, even manual systems have long recognized the need to create primary keys: that's where part numbers, customer numbers, general ledger account numbers, and so on, come from. The mechanism for creating primary keys has historically been a major difference between network and relational databases.
In many network databases, an application can create a record and mechanically link it to another record. That is, the programmer can create an order and say to the database: establish a link between this order record and this other customer record I'm working with at the same time. Invisibly, the network database associates an internal primary key with every record in the system. Each time someone adds an order, the database gives it an internal order number. In the same way, each customer record has an internal customer number. Users don't get to see these internal numbers, but they are there nonetheless.
Here's a simple, everyday way to think about those internal numbers. Recall all the paper forms you've ever filled out in your life (if you can bear to do that). Remember all the forms that had shaded areas to be filled in by whatever bureaucracy you happened to be dealing with. Also recall how many of those forms had specially coded serial numbers on them. Those serial numbers and shaded areas are invisible pointers. When the customs official writes your passport number on a declaration form, he or she is creating a pointer. The driver's license number on the back of a check is another pointer. The magnetically encoded account number on the front of the check is yet another.
Pointers are good, but invisible pointers are supposed to be bad. That's one of the tenets of relational theory. There are supposed to be two problems with invisible pointers:
| If relationships can be based only on invisible pointers created in
advance as part of the database design, how do users get to define new
relationships whenever they need to? | |
| How can a user, or even a programmer, really understand what's going on in the database when some of the data, particularly critical data like pointers, is invisible? |
The last question makes a key point: pointers may be moderately obscure and somewhat subtle, but they are at the heart of what databases are all about -- namely, establishing and using relationships.
It's now time for the second rule in the relational approach to databases. The first rule you already know:
| Normalize all database designs so that redundancy and complex record structures are eliminated. |
287
![]()
Here is the second rule:
| Always use explicit and externally understandable primary and foreign keys. |
What is an explicit and externally understandable key? Explicit means that the key can't be invisible. If, for example, an order record points to the customer record, the pointer takes the form of an explicit (that is, visible in the record, printable in a report, viewable on a screen) customer number. A passport number contained in a declaration record is an explicit foreign key.
Why call out the fact that both the foreign and primary keys must be explicit and visible? If one table is to be able to refer to another, then the pointed to table ( the one being referred to) must have an explicit and visible (primary) key. For example, before a document or table can refer to a passport, the passport records must have the unique passport number column that becomes the basis for the explicit, visible primary key. The same goes for customer numbers, part numbers, and general ledger account numbers. Of course, when you build in the explicit, visible key in the pointed to table, it's a direct consequence that the table doing the pointing uses an explicit, visible foreign key as its pointer.
Why do keys have to be externally understandable? Because it makes database records more understandable. Invisible pointers and invisible primary keys are at one end of a spectrum of understandability: they are not even visible, so they have no meaning independent of the underlying database. A customer's name is at the other end of the spectrum: it is completely understandable and recognizable outside of the database it's in. A goal of relational database design is to have all keys be understandable in the same way. It's a noble objective.
In its purest form, this objective is nothing less than a crusade to eliminate all obscure, special-purpose identification numbers and codes. Few if any database designers have achieved this goal. Nobody would state the goal in as idealized a form as I have, but it is worthwhile to state the most extreme form of this noble goal so that you understand its implications.
Why have passport numbers? Nobody ever remembers them. Why not use the passport holder's name, date of birth, and address? How about driver's license numbers, Social Security numbers, or taxpayer identification numbers? Getting more picayune, why have order numbers, shipment numbers, check numbers, and so on? What happens when you call to trace a shipment and they ask for the shipment number? Perhaps you don't have the shipment number because you never received the package, and they can't trace the package until you provide a shipment number. Sound familiar? Each of these examples illustrates the fact that unique, special-purpose identification numbers, created for literally millions of individual transactions every day, are highly useful inside a computer but highly obscure to everybody outside the computer. These manufactured, unique IDs are both necessary and painfully awkward. Relational database design encourages us to eliminate them.
288
![]()
In practice, eliminating custom IDs is a great idea that is very difficult to fully implement. (I'll discuss this issue in the section detailing the problems of relational databases.) As it turns out, even if some or even many of the keys don't have a meaning independent of the particular database and application, you can still build a fully relational database. The important thing is to ensure that the keys are explicit and visible. If some identifiers have limited meaning away from the database, that's still acceptable. Now that you know that relational tables have explicit, visible keys, how do you use joins to create relationships? With just a little more explaining, all the pieces will be in place.
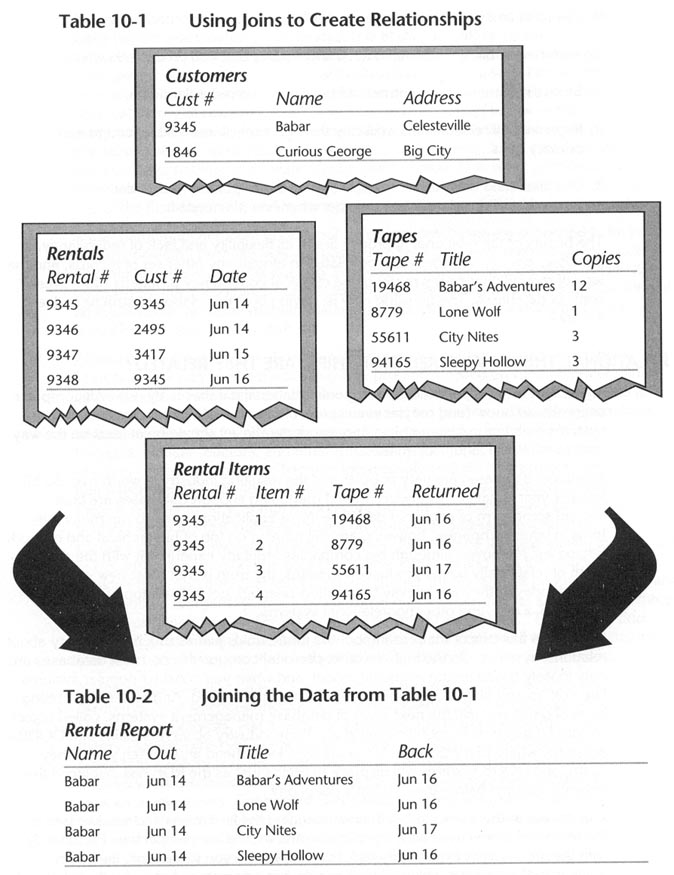
Table 10-1 shows fragments of four tables from the normalized video store database. The samples are fragmentary in two ways: only a very few representative rows are displayed, and only a few of the columns are listed in each row. You can quickly see key fields (like Cust #) in their home tables (Customers) and in their use as foreign keys (Cust # is a foreign key in the Rentals table). Tracing through the example, you should easily see how the arrangement of keys and foreign keys makes it possible to piece together complete records depicting particular rentals. That's exactly how joins work.
A join combines two or more tables into one bigger table based on matching up values in common columns. If you do the obvious join on the table represented in Table 10-1, you end up with Table 10-2.
And there you have a simple join. At one level, the result you see is intuitively straightforward; however, there's really quite a lot going on here. Fundamentally, though, joins do just what they say: they join several tables into one bigger table.
You'll notice in Table 10-2 that some information, such as the customer's name, is repeated quite often. That's a characteristic of joins: as you recombine previously normalized data in which repetitions are common, you naturally see repetitions again. Putting this another way, a non-normalized database stores customer names right in the rental records; the join takes normalized data and organizes it in the non-normalized fashion.
If joins are simply undoing the effects of normalization, what's the point of having done all that normalization in the first place? The trick answer is that joins are temporary operations used to answer a particular question. By storing the actual records in normalized form, you ensure that each data element is stored on disk at only one location. As a result, when that data is changed, the change is automatically reflected everywhere and anytime that data is used. At the same time, by using joins whenever you need to, you can allow that pieces of data to be used in a wide variety of places and in conjunction with a wide variety of other pieces of data. To the user, the reports and records (called views) through joins make the data available in all the places it is used in the real world, while allowing the data to be stored actually only once in the underlying database world. Now that you understand joins, you are ready for the third rule of the relational approach to relationships:
289
![]()
290
![]()
| Use joins as the mechanism for establishing and using relationships. |
To summarize, using relational databases requires that you do the following:
The beauty of the relational approach lies in its flexibility and lack of redundancy. In principle, any set of records can be related to almost any other set of records, and the lack of redundancy solves many of the classical consistency problems (irate president) of databases. The question now is, having built this elaborate structure, does it work?
In theory, everybody should be using only relational databases by now. All computer users should know (and maybe even speak out loud) SQL. Most large production systems built around hierarchical or network databases should be at least on the way over to relational land. Not quite.
Relational databases are very popular and the resulting industry is worth over $2 billion per year in sales. Most large, shared marketing support databases are built around some form of relational database. Most applications used to run major systems in large companies, however, are still running on top of hierarchical and network databases. Moreover, although big companies regularly experiment with the development of relationally based production systems, the truth is that most new systems started today, if they are heavily transaction-oriented, get built on top of IMS, ADABAS, IDMS, and other nonrelational systems.
Not only is this true of the present; but the future holds just as much uncertainty about relational systems. On the high-volume, personal computer front, most databases are only loosely based on the relational model, and when you consider popular systems like FoxPro and dBASE, that looseness is very loose indeed. And at the very cutting edge of database use, the next wave of database management systems, called object-oriented databases, is not relational at all. Many industry observers claim that OODBs are today where RDBMSs were ten years ago: look ahead another ten years, they claim, and OODB systems will displace RDBMSs just as the RDBMSs displaced the network systems before them. What's going on?
The answer to this question lies in understanding the limitations and weaknesses in the relational model from both a pragmatic and theoretical perspective. Fortunately, with the groundwork I've already laid, I can explain to you these limitations very quickly. In the process, we'll review the underlying dogma and see why the relational religion may be its own worst enemy.
291
![]()
As we entered relational land, one of my early observations was that RDBs didn't actually handle relationships. This limitation is at the core of the problem with RDBs as they exist today. Most people assume that the word relational was chosen to reflect an underlying model that expressed relationships in a powerful way. Not so. Instead, as you saw briefly, the term relational signifies a database model based on the mathematical theory of relations. Relations are unordered sets of tuples -- tables. In a simplistic way, relations do represent relationships, but only to the extent that being a part of a table makes a record or a row related to that one table. In an everyday sense, relations have nothing to do with interfile relationships. This is not intended as a negative comment or condemnation; it is a simple statement of fact. I will now deal with one of the first dogmatic, and in my opinion, incorrect myths of the relational religion.
Is the mathematical model important? Relational databases are supposed to be particularly powerful because they are backed up by a complete mathematical model. This mathematical model is not only supposed to impart invincible powers to RDBs themselves, but it also beats competitors by pointing out that they lack the backing of an equivalently powerful mathematical model. So what about the mathematical model? What does it really do?
Almost since the invention of computer programming, idealists and others have searched for a way to either write bug-free programs based on mathematical principles or, if that isn't possible, use those same principles to prove that programs are correct after they are written. As computers and the programs that drive them have become responsible for elevators, antilock brakes, space shuttles, telephone exchanges, nuclear reactors, and other mission-critical applications, the consequences of a bug or malfunction have become increasingly serious. The problem with conventional techniques for building, testing, and supporting software-based systems is that there is no way to be sure that no bugs are present. In theory, elaborate testing, particularly when the test suites are based on years of progressive experience, should produce perfect software. In practice, there's always some last bug arising in some set of circumstances that no one could ever have foreseen and that the testing suites couldn't find. And after that last bug is eliminated, there's always another last bug, and then another. Edsgar Dijkstra, a now famous originator of the "Let's-prove-it's-correct- instead-of-depending-on-testing" movement coined the phrase, "Testing can find bugs, but it can never prove their absence." It is in the context of never knowing when that next bug will appear that mathematical foundations appear so attractive.
Mathematics as a discipline is firmly rooted in the idea of proofs and provably correct theorems. Most sciences, including computer science, are based on experimentation. Develop a hypothesis, test it, look for a pattern, and then propose the hypothesis as a theory that explains part of the world. In most sciences, though, there's no way to prove that a theory is really, truly, and finally correct. As a result, when some new set of observations comes along that breaks the previously observed pattern, it's time to look for a new theory. For hundreds of years, astronomers ( and the rest of us) believed that the sun revolved around the earth. Later, viewing the sun as the center of the universe seemed to be a better explanatory theory. Finally, the current theory views the solar system as just one more planetary system. Each theory was powerful in its time, but each was eventually replaced by another, better theory.
292
![]()
Mathematics, unlike physics or chemistry, is based on absolutes. Each branch of mathematics -- geometry, calculus, algebra, topology -- relies on an initial set of premises and definitions. When that base is in place, mathematicians are able to postulate and prove theorems that then remain absolutely true forever. It is precisely this ability to absolutely prove theorems that is so exciting about mathematics. The Newtonian theory of gravity was exciting and highly useful for hundreds of years, but Einstein's theory of relativity ultimately showed that it was wrong. The pythagorean theorem, however, has been true for thousands of years and will continue to be true forever. Forever and absolutely are powerful adjectives, and it is the certainty that comes with that power that software developers would like to apply to the software users depend on.
Superficially, computer programs and mathematical theorems are very similar. Both are constructed entirely by humans and are based completely on words and symbols. Physics, in comparison, is focused on describing the physical universe, which is assuredly not constructed by humans and certainly based on far more than words and symbols. The fact that mathematical theorems are such verbal and abstract constructions allows people to prove theorems' validity. After all, when mathematicians prove that a theorem is true, what they are really doing is validating its derivation as a set of symbols from another set of symbols representing the premises and definitions supporting that branch of mathematics. If theorems and computer programs are both just sets of symbols derived from other sets of symbols, why can't all computer programs be proved correct?
In theory, computer programs are provable. That's right, at least in theory. It is possible to construct computer programs in such a way that along with the program itself, a programmer could also produce a mathematically sound proof asserting that the program will always do what it's supposed to. Unfortunately, turning that idea into a practical discipline has proven obstinately impossible for the entire time that programmers, computer scientists, and mathematicians have tried.
If it were provably correct that certifiably bug-free programs could be built, the payoff would be huge. For this reason, many brilliant people have expended Herculean efforts in this direction. One approach has involved building special programming languages with mathematically oriented constructs. The idea is that if each of the basic building blocks in a program is provably correct itself, it ought to be easy to build an entire program that is provably correct. Much of the appeal of the relational model revolves around this very idea. Another approach revolves around building special programs which help prove that other programs are correct or incorrect. Yet another approach involves augmenting classical programming languages with constructs that allow various assertions, claims, and premises to be inserted into otherwise normal programs to help in the process of proving them correct. In spite of all this work, when everything is said and done, provably correct programs are as much impossible today as truly artificially intelligent computers.
293
![]()
In a nutshell, programming is an art; it is not a science and certainly not a branch of mathematics. Yes, it would be wonderful to be able to prove that critical applications are bug free. It would be wonderful to even be able to prove that critical parts of those programs would always operate correctly. Wonderful as it might be, it can't be done today.
Before you get too discouraged about all this, try to view it in context: the glass is more than half full. At the turn of the century, mathematicians worldwide, excited about recent advances in formal symbolic logic, believed that mathematics and all of science could be converted to a mechanical footing. Bertrand Russell and Alfred North Whitehead were just completing Principia Mathematica, a massive set of volumes whose purpose was to layout the foundation for all of mathematics. The idea was that with just a little more work, a complete set of definitions, premises, and axioms could be developed on which all of mathematics could be based. Given that foundation, it would then become possible to prove or disprove any theorem by using mechanical approaches alone. The complete Principia could by itself be the foundation for saying whether any proposed theorem was right or wrong. Even though computers and programming had not been invented, mathematicians were involved in the world's first attempt to automate the programming process.
At about the same time as Russell and Whitehead were at work, many historically difficult problems were finally being solved, and thinkers in many countries were predicting the end of science. Physics and chemistry would become complete, mathematics would shift to a complete foundation, and most future questions would become virtually self-answering.
By 1930, the mood of scientists and mathematicians had completely reversed itself based on two sets of developments. First and more well-known, a whole series of theoretical and practical discoveries demonstrated that scientific history was far from over. Relativity, quantum mechanics, advances in organic chemistry , and the discovery of radio proved that invention was still alive. The universe was infinitely more complex than nineteenth century thinkers believed. The second new input, though less well-known, was far more fundamental. That second input was a proof that proofs are limited.
In 1933, Kurt Godel, a young mathematician, published the theorem bearing his name: Godel's theorem. As important in its own way as the theory of relativity, this theorem proves that no matter how complete a foundation of definitions, premises, and axioms may be, there will always be questions that cannot be decided within the theoretical framework of the time. More succinctly, Godel proved that no mathematical system can ever be complete. Every mathematical system will always lead to questions that can't be answered without extending the basic underlying system.
294
![]()
Depressing or exciting? For thinkers preparing for the end of history , it was depressing. Why bother laboring over some ponderous Principia when there's a proof that not all questions can be answered mechanically, no matter how complete the current system? For admirers of human creativity, it was exciting. People will always be required to extend mathematics and science in interesting and unexpected new ways.
Relational databases. Godel's theorem. The search for certainty. They're all related. Bugs are uncomfortable, and not knowing that a complex computer program is bug free is an uncertainty people can easily do without. But in spite of noble efforts, valiant attempts, and Herculean labors, programming is still an art. Trivially simple computer programs can be proven correct; every computer science student learns how. To date, though, no significant or serious computer program has been proven correct, and even the best programmers don't bother spending time trying.
Even core code, that software at the center of critically important programs such as operating systems, databases, and control programs for nuclear reactors, can't be proven correct. In theory, basing a program or part of a program on a solid mathematical footing ought to have a payoff. Maybe one day it will. Today, there is no payoff. So what about the theory of relations and relational databases?
First, as I've already said, the theory of relations deals with tables (sets of tuples) and not with relationships. Even to the extent the theory is useful, it has little to say about one of the most central aspects of databases. Next, as it turns out, even having the theory has surprisingly little practical benefit. For all of the talk of RDBs being based on solid mathematical foundations, when it comes time to build, design, or use data- bases, nothing that happens in the real world relates back in any direct fashion to that supposedly useful theoretical infrastructure. Worst of all, the type of databases described by relational theory turn out to have some significant limitations, limitations that have caused some so-called relational databases to violate the tenets of relational theory .For example, to qualify as a relation, a database table has to be unordered. Being unordered means not sorted by customer name, not sorted by customer number, in fact not sorted by anything. In addition, being unordered means that rows don't even keep any particular order. So if you read through a table and come back to read it again, the rows may be in a different order. Even if you wanted to implement tables that are unordered, how would you do it? Would anybody want a table of that type when you were done? Ordering is fundamental to both computers and people. Reports are always printed in sorted order so that users can find things; computers maintain tables in sorted order so that programs can find things. Unordered collections are an interesting mathematical construct, but when it comes to real life, lack of order is counterproductive. Unordered tables would be hard to build (because computers like order, too), and they would be even more difficult to sell as useful tools if they could be built. Like unordered tables, relation theory as a whole is interesting in theory only. Relational databases that are truly based on mathematics are interesting in theory, but not in fact.
295
![]()
I can now get to the heart of the problem with relational databases: they're too simple for many real-world applications. Simplicity made relational databases popular, and that same simplicity will ultimately make them too limited for the future. Ideally, developers would like to keep that simplicity for small applications while augmenting it to handle the bigger applications.
In what way are relational databases too simple? Well, they don't handle relationships well enough. Ironic, isn't it? A database technology called relational doesn't handle relationships well enough. Relational databases do handle mathematical relations to a certain degree, but those relations are based on single tables and sometimes sets of tables, neither of which is a complete view of the kinds of relationships developers need to build real databases. How do the limitations of relational databases manifest themselves? In two ways: expressiveness and performance.
Remember the steps required to normalize a database? The elimination of redundancy is a payoff, but there is a huge cost. Normalized databases are far more complex to build and to understand than non-normalized databases. They are so complicated that ordinary users have trouble understanding them. The precise characteristics that normalization eliminates turn out to be the cornerstones of understandability. Here are some examples:
| Families don't all have the same number of children. A table doesn't
handle groups of fields, in this case representing children, that occur a
variable number of times. Ordinary people expect tables of records to allow
groups of fields to occur as many times as necessary. Relational databases
say that this is not allowed. The result may have technical and theoretical
advantages, but that same result is hard to work with. | |
| Quite often, putting the line items right into the order record is the natural way to represent a record. Relational tables make this task difficult. Again, intuition, and sometimes performance, asks for one thing; relational theory dictates another. |
At the level of individual records and tables, normalization takes straightforward structures and makes them both less redundant and less understandable. But does normalization have deeper drawbacks?
Normalized databases, at least big ones, are always more complex than they were before normalization happened. Individual records and files, once normalized, turn into more, sometimes many more, simple tables. The individual tables are simpler than the files they replace, but the collection of tables is generally more complex both to work with and to understand than the individual records. The sample video store database, once normalized, required four different tables to be joined to create a simple rental history report (see Tables 10-1 and 10-2).
296
![]()
People who don't make a living working with databases don't understand joins. Joining two tables is tough enough for most people to understand; joining four tables pushes the edge of comprehensibility. Here's the killer: many normalized databases require joins of 10, 15, 20, or even 30 tables to answer relatively simple questions. Users will never understand ten-way joins. They won't learn to do them by rote; they won't figure them out for themselves. They just can't handle joins that complex, and a ten-way join isn't particularly complex by relational standards.
The next problem with joins is that they are very slow to process. Suppose that the average customer rents 3 to 5 videotapes at a time. In a non-normalized representation, each rental record contains all the detailed rental information; that entire record is read all at one time. In a normalized design, the same retrieval requires 4 to 6 reads: one for the rental header record and 3 to 5 more for the individual normalized rental item records. In an order-entry application, orders can easily contain 35 or 40 line items each. What was a single read in a non-normalized system becomes 35 to 40 reads in the normalized database. And the problem doesn't stop with single files.
In a normalized database, every file and every record throughout the database have typically been split up into simpler tables. Departments contain subdepartments; products contain components; orders have line items; teams contain members; employees have dependents; drivers have several cars, and so on. Repetition and variability in occurrence are standard parts of the universe. Normalized databases invariably have to convert a set number of files into 3 to 10 times as many simpler tables. The tables are simpler, but the overall database isn't. And when everything is normalized, routine operations -- reports, queries, transactional updates -- take 3 to 4 times as many disk operations and 3 to 4 times as much computer time to process.
For small- and medium-size applications, taking 3 to 4 times as long is acceptable; for big applications, it isn't. So you can see why departmental applications and decision-support applications run on relational databases while the bigger applications that drive the business don't. But what about the idea that relational databases are simpler? Is the idea itself wrong? Where did the idea come from if it's wrong?
Back in 1973, when Bachman first pronounced the programmer as navigator, databases were hard to use -- hard to use because all software was hard to use in the 1970s. Word processors (yes, they existed back then), electronic mail systems, accounting software, databases -- in fact, all applications were just plain hard to use. GUIs had not been invented; mice were known by only a select few; interactive computing was just becoming popular. It's hardly surprising that as the idea of querying a database dynamically was being invented, at first it was darn hard to do.
Even as recently as 1981, word processors, spreadsheets, and most other now common applications were still so hard to use that most office workers needed extensive training just to produce simple memos with a computer. So when relational databases were being invented, databases were hard to use, not because of intrinsic limitations in the network model, but because software in general was still hard to use. The techniques and tools required to make software approachable were still to be invented.
297
![]()
The relational revolution did introduce several valuable ideas to the database world:
| Tables are a simple way of presenting data to users. Spreadsheets
later confirmed the intuitive appeal of this representation. | |
| Interactive querying: Retrieving and manipulating data dynamically
is what databases are all about for many everyday users. | |
| SQL (pronounced sequel) is a very convenient standard query
language for database tools and database professionals to work with data in
a database- independent fashion. | |
| High-level, set-oriented operations allow both programmers and
ordinary users to find and work with large collections of records at one
time without having to write programs. | |
| Joins are a very powerful tool for linking previously unrelated records. Through the combination of the join operator and the ability of a query tool to support temporary tables that display the joined result table, users can create new sets of related records on the fly to explore and work with relationships as the need arises. |
This powerful legacy helps explain part of the appeal of relational databases. The true appeal is simpler, though. IMS, IDMS, Total, ADABAS, and all the other early databases, whatever their underlying model, were designed for programmers. Even after query languages were added, they were still hard for non computer professionals to learn and use. Relational databases, on the other hand, were designed from the beginning to be easier to use. Easier, as you'll see, does not mean easy; just easier.
Relational databases became popular at just about the time that minicomputers and departmental systems were taking off. In the 1960s, mainframes were built to serve the needs of entire divisions or companies. By the late 1970s, departments (marketing, sales, engineering, and so on) within large organizations began purchasing relatively inexpensive minicomputers to serve the needs of white-collar professionals. The precursors to today's high-powered engineering workstations, these systems, although still too expensive for individuals, could be shared among groups of individuals. The applications running on these departmental systems -- marketing analysis, simple financial forecasting, engineering analysis -- were simpler than those on the mainframe. These applications were typically built by programmers, but the requirements placed on those programmers were simpler. It is for this class of applications, still programmer oriented but with simpler requirements, that the early relational databases were ideally suited.
Tables are a simple way of representing data: a programmer can explain a table to a user in a few minutes. For simple applications involving only a few tables (less than
298
![]()
20), a relational database allows applications, queries, and reports to be constructed quickly and easily. As DEC grew to become a $10 billion company selling depart- mental minicomputers, Oracle grew to become a billion-dollar software company selling relational databases to go along with DEC's VAXes. So a lot of the popularity of relational databases has to do purely with timing. As the third generation of database technology and the second generation of query programs, relational systems were the first to be even moderately easy to use. Because they were developed at just around the same time that departmental minicomputers were taking off, there was a market wave for them to catch and ride.
Two acid tests allow us to draw correct conclusions about the true success of relational databases. On the ease-of-use front, relational systems are just not particularly easy to use. Neither Oracle nor DB2 was the first to be used by housewives, school- teachers, salespeople, and millions of others. That distinction is reserved for 1-2-3, dBASE, and Paradox. Neither the underlying relational model nor SQL achieved the appropriate ease-of-use breakthrough required for true bestseller status, and the databases that did achieve this break-through ended up being nonrelational in nature. Even when it comes to handling multiple tables at one time, products like Paradox and PowerBase made this everyday task easy without using the relational model. To be clear, this does not mean that the relational model somehow failed; it is simply neither necessary nor sufficient for true ease of use.
What about the big applications? Until recently, the verdict has been out on whether the relational model would eventually turn out to be the best for running businesses. During the 1980s, normalizing databases resulted in applications that ran too slowly. However, many relational enthusiasts insisted that this problem would disappear as computers continued to get faster and as relational database vendors invented newer and more clever techniques for dealing with normalized databases. In the end, the issue has been decided on grounds that have to do with more than just raw efficiency.
Representing large databases in a relational form turns out to be a problem for both humans and computers. People have not become able to deal with 20 or 30 table joins, and the cost of building those large joins continues to be an issue even as computers have become faster. In one typical banking application, for example, all the queries executed by branch staff -- several dozen -- all turned out to involve more than 20 joins of tables. If you normalize tables, you create a need for joins.
The first thing that happens when the price for normalization is realized is that database designers start denormalizing the very database they started out by carefully normalizing in the first place. Rather than dynamically create the understandable joined tables as circumstances require, designers choose instead to build and maintain these tables as permanent parts of the database. In fact, having a catalog of such denormalized views is standard procedure in any large decision-support environment.
299
![]()
The implication of the decision by organizations worldwide to use these denormalized views is simple: they are going back to the network model of the 1970s. Denormalized views are nothing more nor less than complex record structures stored directly in the database. And this shift back to network structures goes much further.
A typical large relational database can easily have 50 to l00 tables. Databases with hundreds of tables are not uncommon. One complete, high-efficiency, and widely sold financial software package, built by SAP, has over 5,000 distinct tables in it. Finding your way around a database with 50, 100, or 5,000 tables is by no means easy: you need a map.
Of course, one way to build such a map is to use the type of data model shown earlier in this chapter: a network system. Why not have the database support the data model internally? In theory, every table can be related to every other one. In practice, although not every table in a database is related to every other one, keeping track of all those relationships turns out to be just as important as keeping track of the data in the first place.
With this realization, the result has been the development of the object-oriented database, or OODS. Object-oriented databases have caused as much religious hype as the relational model once did. Considered from a pure database perspective, OODSs have three unique features that distinguish them from RDSs:
| Complex record structures, including repeating groups of fields, can be
represented directly in an object-oriented database. Employees can have
multiple children; orders can contain line items directly; parts records can
describe their subparts. | |
| Relationships between files can be stored directly in the database. Records |
300
![]()
can point directly to other records.
| Programmatic behavior can be associated directly with particular classes of records. When a customer record is deleted, the linked code can automatically delete outstanding orders. |
Those first two attributes of OODBs sound suspiciously similar to a description of network databases -- because they are similar. OODBs in many ways are just grown-up network databases. Period. The third attribute -- the capability to link data to programs that get executed directly when certain events happen -- is an important new idea, but that idea, called triggers in database-speak, has been available in relational databases since 1987 and could just as easily be added to an older network database. (Triggers, in fact, are exactly events that get raised by the database. These events are then associated with particular pieces of code that are executed.) In style, OODBs are more modern than network databases, but in substance, they represent a return to the network world of the past.
Does this mean that relational systems will disappear? Is the relational model some- how wrong? Not likely, and no. So what is happening?
Bachman was right: programmers are navigators on an ocean of data. Databases are about relationships between collections of records, and these relationships must be expressed directly in the database. When the database stores the relationships directly, navigating through the network of those links, both dynamically and passively, is a very important and exciting thing to do. Relationships need to be expressed at three levels:
301
![]()
admit the truth and build databases that support both visible and invisible interrecord links? That's what OODBs do.
By recognizing the importance of both the relational and the navigational models, it becomes possible to build next-generation databases that provide the best of both worlds. One can admit that Bachman was right after all without necessarily insisting that Codd (and relational systems) are wrong.
As 1995 draws to a close, network, relational, and object databases compete with each other in somewhat different application domains. The problem is that developers (and the users they serve) are forced to choose between all the different competing models, which creates a set of essentially impossible choices. The question is this: What's the alternative? The answer revolves around understanding the one common design element true for virtually every production database design in the world today: monolithic construction. That's right, database systems, whether old or new, are built in a completely monolithic fashion. In some ways, this represents the supreme irony. On the one hand, the community of developers who build the database systems themselves includes some of the smartest, most highly educated and widely read developers and designers anywhere. The professionals attend conferences, keep up with modem tools, and truly represent the state of the art. Yet, when it comes to writing their own software, they build the most monolithic systems to be found anywhere. Database builders trust no one! Use the operating system's buffer manager? Never. Share a transaction manager with another software system? No way. Build it all in, make all the interfaces proprietary , and there you have a database system, whether new or old. The question now is this: What would happen if you built a database itself out of cooperating components? To gain some perspective on this question, the following starts by recapping where the world is today.
Network and hierarchical databases still contain the vast majority of the world's production data. Only these systems can handle both the volume of data and the complex linkages between files that big applications require. Relational databases are broadly used for departmental applications. An increasing number of organizations
302
![]()
are experimenting with the construction of distributed client/server systems with RDBs running on each server. Finally, OODBs are starting to gain a strong presence by supporting a new class of databases with moderately large collections of records with extraordinarily complex sets of interrecord relationships. For example, designing a car or airplane involves working with thousands of parts all arranged in a highly complex bill of materials. Computing the structural strength of a particular design involves chasing through all the hundreds of those parts over and over. In this environment, OODBs turn out to be over twice as fast as RDBs because they handle all the relation- ships so much more simply and efficiently. So there you have an overview of the leading models for serious OBMSs. Network systems are fast; relational systems offer flexible analysis; OODBs support rich data structures. Which do you want? All three? But you have to choose, and the problem doesn't end there.
While IMS and IDMS contain the majority of the production data in large organizations, the majority of the total data is contained somewhere else. In fact, it's not in databases, as we know them today, at all. Where is it? In spreadsheets, project managers, in Notes' "databases." And a great deal more data is in dBASE, Access, Paradox, Fox, and other desktop databases that, too, are never counted when figuring out where the world's data is stored. All these desktop and workgroup data stores contain over half the world's structured data.
To be very clear about what kind of data I am talking about, consider the following fact. Over 80% of spreadsheets contain no formulas other than column totals. What they do contain is tables of records. All project management packages are built up around tables containing records. Over 5 million Access users certainly are building tables containing lots of records. So when I talk about the half or more of the data not contained in classical databases -- whether network, hierarchical, relational, or object- oriented -- it is exactly and totally database data I am talking about. It's time to start thinking about that data as part of the database world, too.
This is precisely the problem of heterogeneity that we talked about when I
first introduced the concept of cooperating components. The question is, how
does that concept help solve the problem? To see how this works, take a look at
how the classical database is structured.
| Forms |
| Programming Language |
| Query Processor |
| Transaction Manager |
| DB Store |
As this list shows, a database consists, internally, of a number of components, each with a specific job to do. For instance, inside every DBMS is a record storage engine that reads from and writes records to disk, building indexes to allow rapid retrieval,
303
![]()
and so on. Similarly, every DBMS has some form of query processor that takes
a query (in SQL or some other language) and then figures out how to find the
data being asked for. The problem (as you'll see) is that these components are
all glued together, not interchangeable, and not even accessible to the outside
world. Okay, now it's time to change that (see Figure 10-8).
Figure 10-8. The OLE DB model.
Pick a database. It has a query processor. Now what is required for that query processor to be able to get at tables in a spreadsheet? The answer is "an interface." Or in slightly more detail, a set of predefined subroutine calls so that the query processor can do the following:
| Ask the spreadsheet what tables it has. | |
| For each table, ask what columns are present and what their datatypes are. | |
| Ask for the values of rows in the tables. | |
| Ask for changes to be made to those rows, for new rows to be inserted, and soon. |
While such an interface clearly could exist, no one has defined it yet. At least not until very recently. I am not talking about SQL! Nor am I talking about interfaces, such as ODBC, which are designed to allow applications to talk to SQL based databases in a standard way. Why not? Well, a spreadsheet is not a database; neither is a project manager or an ISAM file package. Asking a spreadsheet to speak SQL is like asking it to become a database. If every application and tool that stored data could just become a database, then this entire discussion would be largely unnecessary .No, something different is needed.
Every database has the interface I am talking about. Every database has some form of interface that allows its query processor to talk to its underlying store. The problem is that those interfaces are not published and are not standard.
304
![]()
Early in 1995, Microsoft began the process of disclosing to the world of developers the details of a set of interfaces called OLE DB, also sometimes called OLE Database. This chapter will look at OLE itself more closely later, but suffice it to say that OLE, and its underlying COM (short for Component Object Model) represents Microsoft's broad framework for building objects. Within that context, OLE DB is a prescription or framework for recasting databases themselves as sets of cooperating components.
OLE DB is a relatively technical set of interfaces (specified in C and C++) that describes how any two components that work with tables and sets of records can interoperate. In OLE DB parlance, such components are called tabular data providers or TDPs.
A TDP can be a complete relational database that speaks SQL, but it doesn't have to be. A TDP, purposely, can also be a much simpler component, like a spreadsheet, word processor, or project manager that understands simple collections of records and not much more. By then adding "external" components like a query processor to the picture, it becomes possible to formulate SQL queries that retrieve data from a spreadsheet without the spreadsheet having to be a database or having to speak SQL, How does that work?
By publishing OLE DB as a potential standard interface specifically designed to sit between the previously internal components of a database, the way becomes clear to rearchitect databases themselves so that they become sets of cooperating components, too. It's now time to explore some interesting scenarios that arise from this new picture of the world:
| Users can store data in the container of their choice. One user can build
budget forecasts in a spreadsheet, another in a project manager, and another
in a true database. An OLE DB based query processor, previously an
inseparable part of a monolithic database, can combine data from all these
many datasources as though it was all one big database. The user of the
query processor, once an SQL query has been entered, can't tell where the
data came from. | |
| Many of the world's production applications run on ISAM file systems and hierarchical databases because those systems are so fast. Yet, inside every relational database is an ISAM style record store (is it struggling to get out?). By componentizing the database in this way, that underlying record store becomes directly available to developers, through the OLE DB interface. Many developers will choose to continue treating the entire system as a relational database, accessing data only through the query processor and SQL. Other developers, though, may need the additional performance, be willing to do the extra work of developing their own retrieval strategies, and use the underlying record store directly. In both cases, the data still ends up in the common database -- accessible to all and consistent in nature. |
305
![]()
| What happens if you replace the query processor? The first example
considered the idea of being able to store data in a wide variety of storage
containers, using all your favorite tools to create and edit data while
still having that data accessible by way of the familiar SQL based query
processor. Essentially, you have a "replaceable" storage engine.
Why not be able to have a replaceable query processor, as well? | |
| The next version of the block diagram (see Figure 10-9) shows a query
processor that understand maps and geography -a geographical query
processor. More than likely, it works primarily around maps projected on the
screen. If it has a query language, that language is almost certainly only
vaguely related to SOL. |
Figure 10-9. An updated version of the original block diagram.
| Does a query processor even have to provide a query language at all? The DBMS, the spreadsheet, the ISAM, and the other containers at the bottom of the diagram are all physical containers; they contain actual records, often entered by users. A query processor, on the other hand, is essentially a container that holds logical records -- records derived from the underlying physical records in the other containers. In the database world, sets of logical records are often called logical views. Generally, logical views are defined in terms of SQL queries, but this is not a requirement. Given a relational data- base, though, it is hard to build a true logical view any other way. Consider the following problem. Suppose that I'm building an Information Warehouse, as was discussed in the last chapter. As part of the project, I write a program that performs a particularly complex form of profitability analysis. The result |
306
![]()
of this analysis is a table: profitability by product, but computed in this complex and changing fashion. Now, here's the catch. I've generated this table, but I don't want to store it anywhere because the contents of the table change according to a wide variety of external factors; if I store it, the table becomes static. Yet, at the same time, I want users to be able to work with this table just like they would work with any other table. For example, a user might want to use Access or Paradox to join this table to several other tables, physical and logical. How do I make that possible? There is an answer, and it's actually quite simple.
First, I write my computational calculator program using any programming language that makes sense. Then I build the OLE DB interfaces into my program. The profitability calculator appears to the overall database system just like any other container with tables in it. Even though all the values in my tables are calculated and derived, those values still look exactly like normal database tables to all external consumer. So a query processor, Access, or some completely different application written to talk to OLE DB directly, the tables I generate are just that -- tables; the fact that values are calculated is made transparent. Now, here's an interesting twist on the whole theme. Not only can the user of my tables look at them, the user can change the table, too, if I just allow it. For example, suppose that my table contains a column with a calculated "standard cost." Depending on how I set security permissions, users (apps or people) can change the value of that standard cost, and then the profitability calculator does the right thing automatically. That right thing might be as simple as recomputing profitability for a row, or it may be as complex as modifying dozens of underlying base tables affected by the new standard cost. The beauty of the scheme is that to the consumer of the table it's just that: a table, available for examination and update.
The last example, in some ways, is the most interesting because of its far-reaching implications. One of the leading database trends of the '90s is the increasing popularity of object-oriented databases or ooDas. One of the key features of such systems is their capability to take advantage of very large amounts of memory in either a workstation or a server. The rightmost box in the most recent diagram shows a component called an In Memory Database (IMDa). At one level, this is a query processor, a container holding logical records, all of which originally came from a physical container. Another way of looking at such a container is that if the container is located on a workstation, for example, it could be a staging area, or cache, for holding all the data a user, or the user's application, is working with, thereby taking advantage of arbitrarily large amounts of memory to improve performance. At this point, the combination of the IMDB and the underlying record store is the moral equivalent of a full OODB. OODBs do support richer data structures than classical RDBMSs; however, suppose that the underlying record store was
307
![]()
augmented to support the same richer data structures. What would you have then? It is interesting to think about what core extensions are required to make a classical "flat" or ISAM-like record store capable of dealing with complex records. In fact, only three extensions are required. While there isn't space here for all the details, suffice it to say that by adding GUIDs (Globally Unique Identifiers), pointers (which are just GUID valued fields), and embedded tables (allowing individual columns / fields to contain complex values that are tables or structures in their own right), you end up having a complete system. Ironically, you end up with an underlying record store that looks very similar to older systems such as IMS, ADABAS, Cullinet, or Pick.
Putting all the examples together and building databases over again around the concept of cooperating components saves us -- developers and users -- from making impossible choices. Even more important, it saves databases from becoming irrelevant just as you need them most of all. Being forced to choose between flexibility, performance, and richness of data structure is an impossible choice. However, in a world of componentized databases, you can have all three. A rich variety of underlying record stores can offer the same data structures and performance that have kept large applications tied to ISAM, IMS, and IDMS for the past 30 years. Certainly, organizations will not convert their applications from these older data stores just because the performance can now be available. The rest of the cooperating component story, with its support for ubiquitous commodity computing in a highly distributed environment, is required to provide the complete motivation to make that shift happen.
Once the motivation is there, however, having that performance will suddenly become critical. The performance may not be sufficient to motivate a shift, but it is certainly necessary to allow that shift to happen when the sufficient reasons are there. Componentized query processors allow you to also have the flexibility you associate with relational databases, but now that flexibility is actually amplified. Not only can you join tables created in the RDBMS in the first place, but you can also join tables created in a wide variety of other containers, as well. There's no tradeoff between flexibility and performance, per se, since it's up to the developer whether he or she writes directly to the underlying data store for performance or chooses to work completely through the relational query processor for flexibility and reduced programming effort. Finally, as record stores grow in sophistication and IMDB components become available, even OODB applications become possible -- and they become possible without having to install yet another disjointed database into the environment. Data in the IMDB arrives from the same containers as used by all other applications; however, in the IMDB, large amounts of memory , optimizations to support pointers, and direct linkages to languages like C++ support applications that perform complex operations on rich data structures. Performance, flexibility, rich data structures -- you can have
308
![]()
them all; thanks to cooperating components.
Beyond the impossible choices, there is a real risk that without componentized databases, DBMSs as we know them today could be passed by, and in a very real way. Thinking about half or more of the world's structured data sitting in containers that aren't databases in the commercial sense of the word is a pretty scary thought. It is scary enough to make one wonder which is the tail, and which is the dog. However , component databases change the framework to include these data stores as first-class citizens in our database world. Databases then become mainstream in every sense of the word. The only question is can a shift as large as the shift to component database even happen?
Database technology shifts are not only possible, they're also compelling and perhaps even essential. Things will change in the database world, but the stakes this time around are far higher than ever.
Database designers made history in the 1970s when they built production applications based on network and hierarchical databases. History changed when relational databases took off, providing the foundation for departmental systems. In this decade, a new generation of complex applications has fueled the adoption of object-oriented databases. Most recently, history has seen the widespread adoption of easy-to-use, PC-based databases by millions of desktop users. Each of these shifts has been associated with relative rearrangements of the commercial landscape as corporate startups became leaders only to be eclipsed by the next generation of startups. In the end, though, relational databases did not replace network databases, and, at least until now, the PC database has not replaced either of its predecessors. Somehow there has been room for them all, but that room exists at the expense of having all of these databases run in an essentially disconnected fashion. What this history tells us is that, at least in database land, there is room for fundamental paradigm shifts. And perhaps this will be the paradigm shift that also makes all the DB pieces fit together at last.
Okay, so now you understand databases and where they are going. As promised, cooperating components playa key role in that evolution. But what about using those databases to build all those highly distributed applications? How is that done? That's what the next chapter covers.